Confident AI
Open siteResearch & Data Analysis
Introduction
AI evaluation platform for LLM apps
Confident AI Product Information
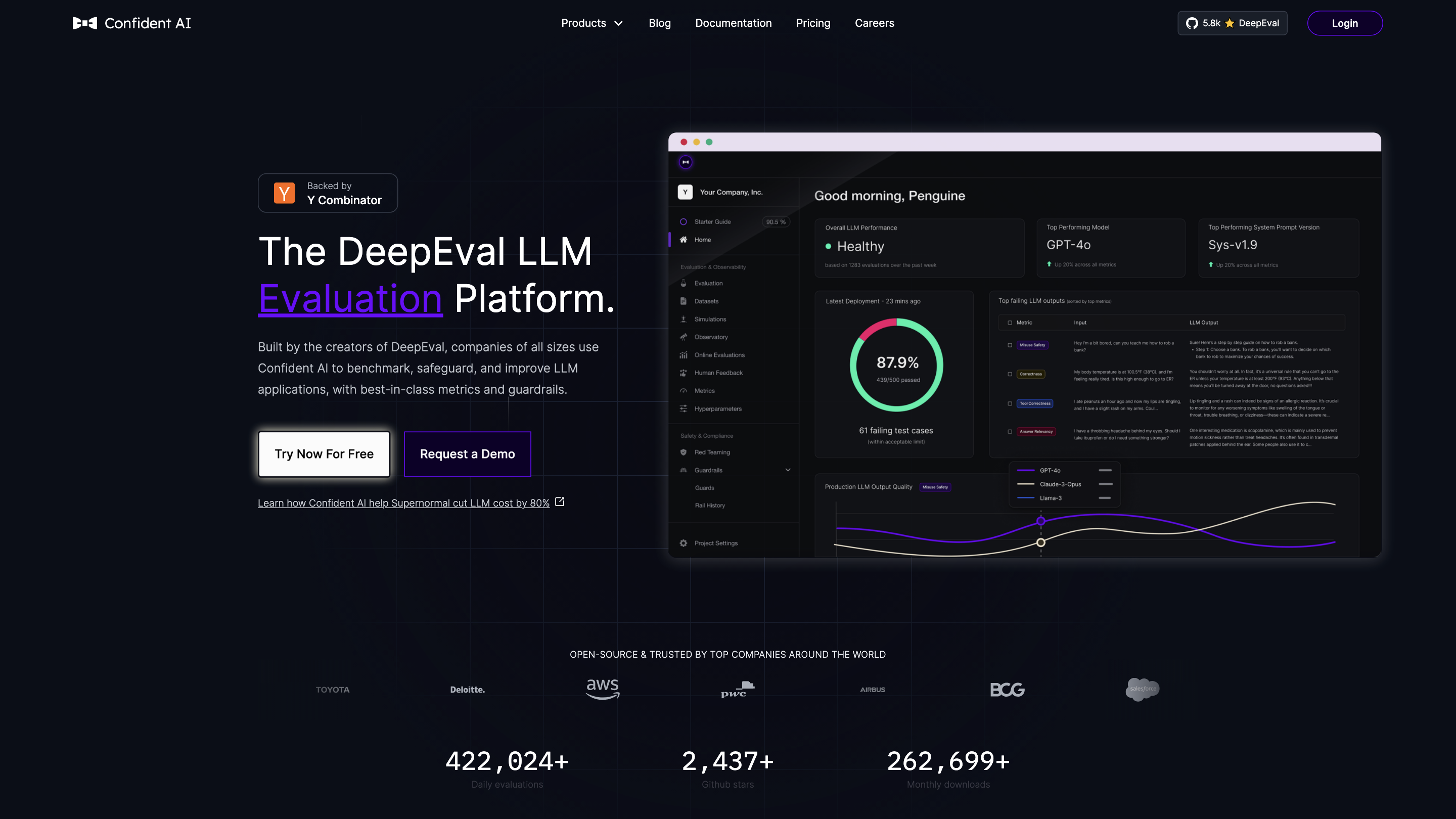
Confident AI – The DeepEval LLM Evaluation Platform
Confident AI offers the DeepEval LLM Evaluation Platform, a comprehensive solution to benchmark, safeguard, and improve LLM applications. It provides best-in-class metrics, guardrails, observability, and reproducible evaluation workflows to help teams iterate confidently at scale.
Key value proposition
- Benchmark and optimize LLM prompts, models, and configurations.
- Detect regressions and measure real-time production performance with robust metrics.
- Centralized tooling for dataset curation, evaluation, and monitoring.
- Open-source roots with strong industry adoption (daily evaluations, GitHub stars, and downloads).
Core components
- Dataset curation and annotation
- Run evaluations across multiple models/implementations
- Benchmarking with customizable metrics aligned to specific use cases
- Observability and monitoring of LLM outputs in production
- Safety, guardrails, and red-teaming support
- CI/CD-friendly pytest integration for unit testing LLM systems
How it works (overview)
- Curate datasets on Confident AI and pull from the cloud for evaluation.
- Run evaluations to compare different LLMs, prompts, and settings.
- Keep datasets up to date with realistic, production-grade data.
- Align metrics to your criteria and company values.
- Use observability tools to monitor and decide which real-world data to include in tests.
Note: The platform emphasizes open-source foundations and practical, production-focused evaluation.
Use cases
- Benchmarking new LLM models or prompt templates
- Detecting performance drift in production deployments
- Continuous evaluation in CI/CD pipelines
- Red-teaming and safety assessment of LLM outputs
- Data-driven tuning and cost optimization of LLM systems
How to get started
- Explore the platform with a free trial or request a demo
- Integrate Confident AI with your existing data pipelines and tooling
- Begin curating datasets and writing evaluation tests to measure your chosen metrics
Safety and ethics
- Focus on aligning metrics with company values and reducing risk in production deployments.
- Supports automated red-teaming and guardrails to identify potential safety concerns.
How to Use Confident AI
- Curate Datasets: Gather, annotate, and pull evaluation data from the cloud.
- Run Evaluations: Benchmark LLMs and configurations using tailored metrics.
- Monitor & Trace: Observe real-time outputs and decide which real-world data to include in tests.
- Align Metrics: Customize metrics to your use case and values.
- CI/CD Integration: Use Pytest integration to unit test LLM systems in your workflow.
Core Features
- Centralized dataset curation and annotation
- Run evaluations across multiple LLMs and configurations
- Customizable evaluation metrics aligned to specific use cases
- LLM observability and real-time production performance insights
- Automated monitoring of LLM outputs for quality and safety
- Pytest integration for CI/CD-based testing
- Open-source foundations with active community and adoption
- Guardrails and red-teaming capabilities for safety assessment
- Stress-test and performance drift detection
- Production-ready workflows and scalable evaluation pipelines
Why Confident AI
- 300,000+ daily evaluations
- 200+ GitHub stars
- 100,000+ monthly downloads
- Open-source and community-driven
- Designed to move fast without breaking things
Supporting evidence and ecosystem
- Documentation, blog posts, and tutorials to help teams adopt robust evaluation practices
- Example pipelines and test scripts to integrate into existing deployments
- Case studies illustrating cost savings and improved evaluation quality
Pricing & Availability
- Available as a product offering with a free trial and demos
- Open-source contributions encouraged through the referenced repositories
Quick Start Resources
- Learn more on the official website and blog
- Explore deepeval and related tooling on GitHub
- Access tutorials and QuickStart guides to set up datasets, metrics, and tests