DVC AI
Open siteResearch & Data Analysis
Introduction
Revolutionize ML Data Management
DVC AI Product Information
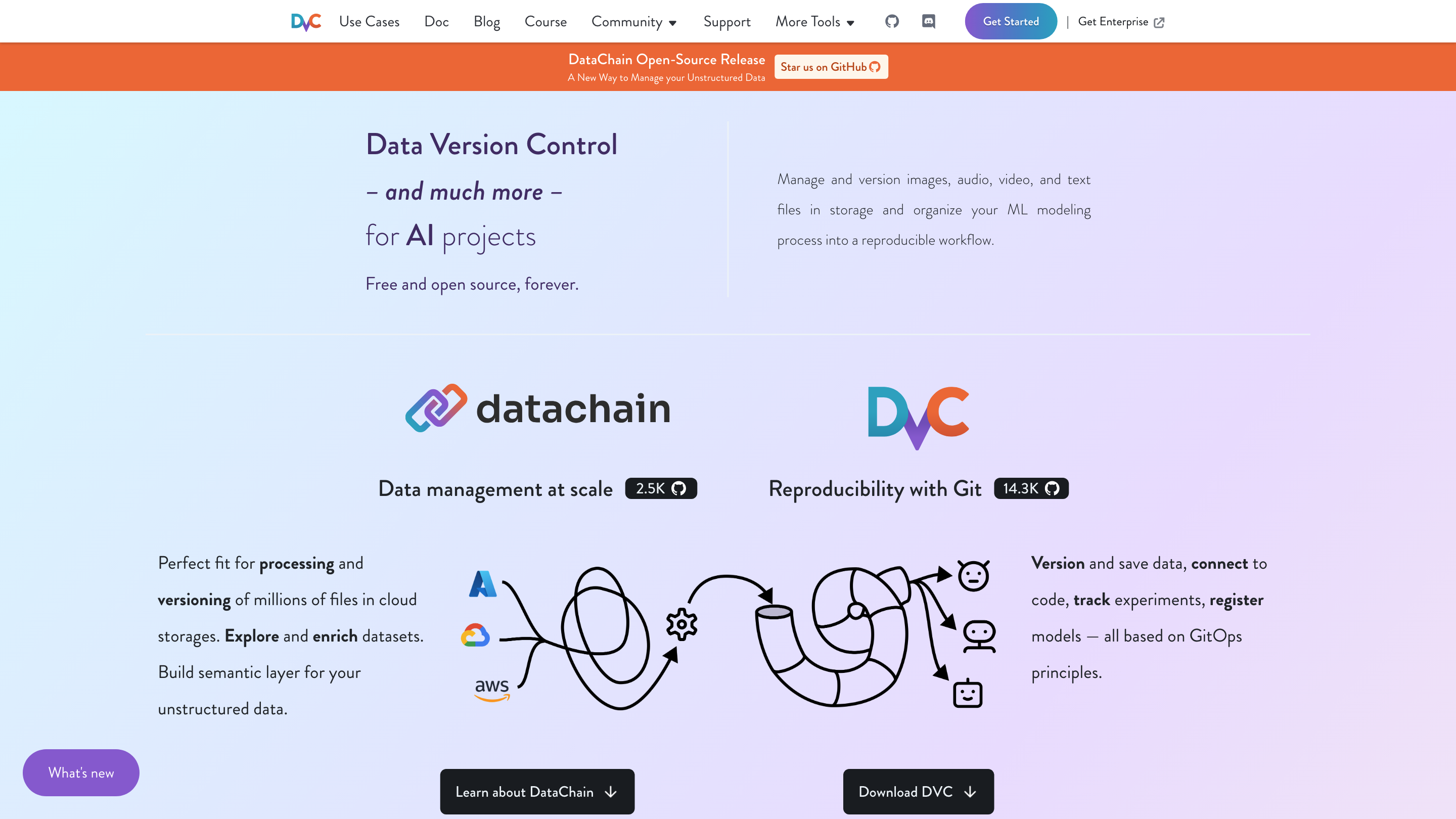
DataChain & DVC (Data Version Control) Overview
DataChain is the open-source ecosystem around DVC (Data Version Control) designed to manage unstructured data and AI workflows at scale. It provides GitOps-based data and experiment management across datasets, code, models, and pipelines. The tooling emphasizes reproducibility, scalable data handling, and collaboration for ML projects from open source to enterprise deployments.
What it enables:
- Versioning and managing large unstructured data (images, audio, video, text) alongside code and models.
- Building reproducible end-to-end pipelines that connect datasets, code, and models.
- Experiment tracking, dataset querying, and metadata capture without duplicating data.
- Collaboration across teams with Git-like workflows and cloud storage integration.
How DataChain & DVC Work
- Version data without copying. Create and version datasets without duplicating data; metadata and references are tracked instead of raw data.
- Connect storage to repo. Link your cloud storage to your code repository so data, models, and results are accessible in the same workflow.
- Declare steps and dependencies. Define pipeline steps with inputs/outputs to build reproducible, end-to-end workflows.
- Track experiments in Git. Save complete experiment states, compare results, and reproduce runs across teams.
- Manage large datasets at scale. Designed for billions of samples with efficient metadata and storage-backed data management.
Core Concepts
- Git-like versioning for data and experiments
- Data pipelines that connect datasets, code, and models (GitOps-style)
- Metadata-driven rather than data-copying approaches to keep data management scalable
- Cloud storage integration for sharing and collaboration
How to Get Started
- Install DVC and its VS Code extension to integrate data versioning into your developer workflow.
- Connect your storage backends (S3, GCS, Azure, etc.) to your repo.
- Create datasets from queries or data sources and version them without copying data.
- Define pipelines and run experiments, then compare results and roll back if needed.
- Use the DVC Studio and related tools to visualize experiments and manage collaboration at scale.
Use Cases
- Versioning millions of files in cloud storage with GitOps principles
- Building reproducible ML pipelines from data ingestion to model training
- Experiment tracking across teams and environments
- Enriching datasets and constructing semantic layers for unstructured data
Safety & Legal Considerations
- Ensure data privacy and compliance when versioning and sharing datasets.
- Use metadata and provenance responsibly; avoid exposing sensitive information in experiment records.
Core Features
- Open-source, free, and forever accessible
- DataVersion Control for unstructured data (images, audio, video, text) and ML workflows
- Version datasets without copying data; track metadata instead
- GitOps-based data, code, and model management
- End-to-end pipelines linking data, code, and experiments
- VS Code Extension for integrated development and experiment tracking
- Cloud storage integration to host data alongside code
- Experiment tracking with easy comparison and reproducibility
- DVC Studio for project-level insights and collaboration