Fleak
Open siteCoding & Development
Introduction
Low-code API builder for data teams to simplify AI workflows.
Fleak Product Information
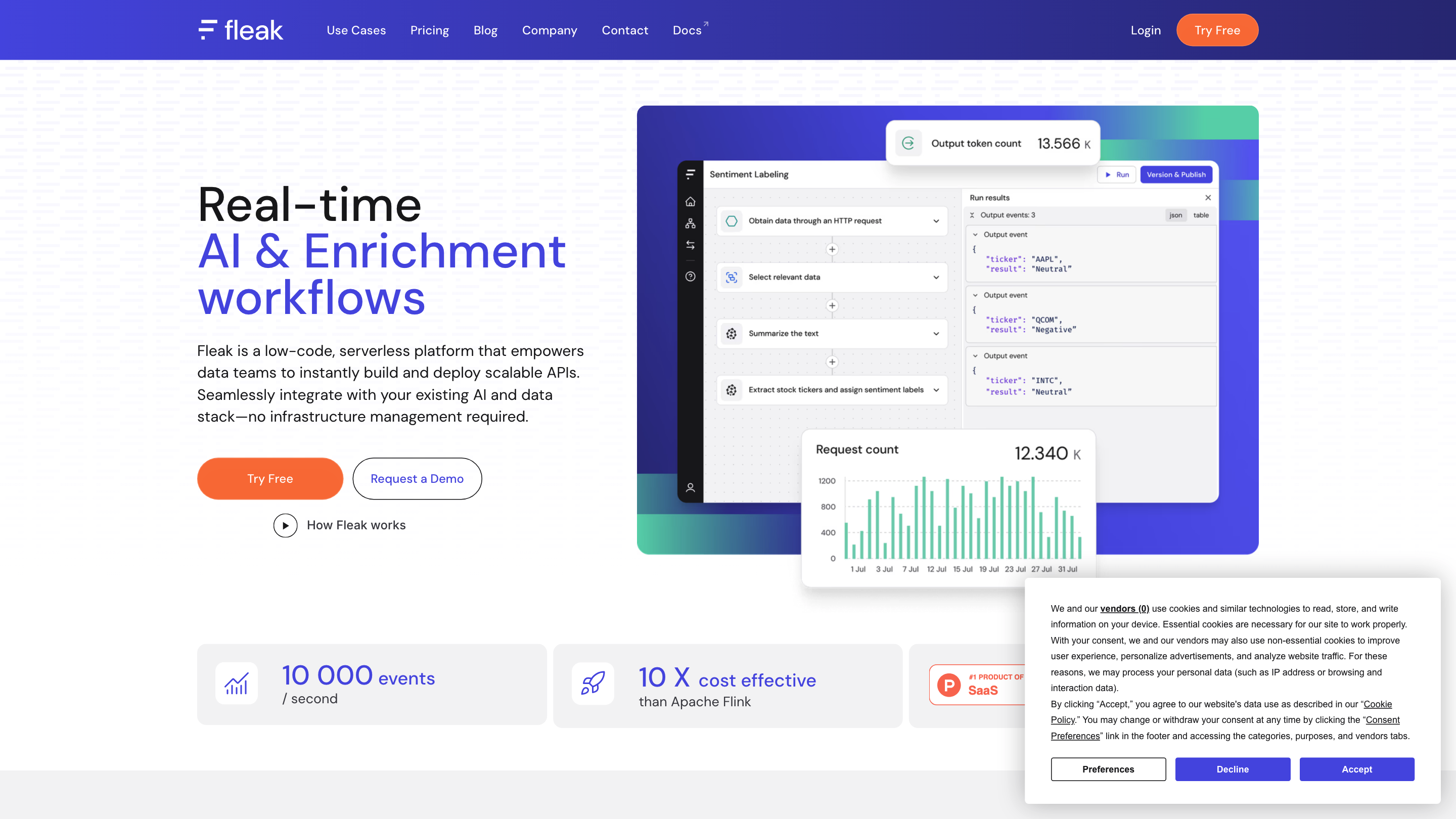
Fleak AI Workflows: Real-time AI & Enrichment with a Serverless API Builder
Fleak is a low-code, serverless platform designed for data teams to instantly build, deploy, and scale APIs and AI-powered workflows. It seamlessly connects to your existing AI and data stack, removing infrastructure management and enabling rapid iteration from data to production APIs.
Overview
- Build data workflows quickly using a visual, node-based editor that supports JSON, SQL, CSV, and plain text data.
- Integrate with leading AI models, databases, and storage services (e.g., GPT-family models, LLMs, vector databases, AWS Lambda, Pinecone, AWS S3, Snowflake).
- Publish, manage, and monitor APIs with versioning and production-grade endpoints.
- Serverless architecture minimizes operational overhead, enabling focus on logic and insights rather than infrastructure.
How Fleak Works
- Create and configure workflow nodes. Define data transformations, embeddings generation, and data routing using a low-code interface.
- Connect AI models and data stores. Integrate large language models, vector databases, storage, and other essential tools to orchestrate AI-enabled data workflows.
- Transform and enrich data. Process data types like JSON, SQL, CSV, and plain text; generate text embeddings; and route results to storage or downstream services.
- Publish and monitor APIs. Version workflows, push to staging/production, and monitor performance and data accuracy from a single platform.
Use Cases
- Building production-ready AI data pipelines and APIs in minutes
- Real-time data enrichment and orchestration across LLMs and vector stores
- Data-to-API workflows that scale with minimal infrastructure management
- Rapid experimentation with different AI models and storage backends
How It Helps Teams
- Data scientists, data engineers, and software engineers can collaborate on AI-driven workflows without heavy DevOps.
- Centralized management for API endpoints, versioning, and monitoring to reduce time-to-value.
- Storage-agnostic design for flexible integration with cloud data warehouses or lakehouses.
Core Capabilities
- Low-code, serverless platform for building and deploying AI-enabled APIs
- Visual workflow editor supporting JSON, SQL, CSV, and Plain Text data
- Seamless integration with AI models (GPT, LLaMA, Mistral, etc.) and LLM orchestration
- Connections to vector databases, AWS Lambda, Pinecone, and modern storage (AWS S3, Snowflake, etc.)
- In-memory SQL and LLM nodes for low-latency processing
- Publish, version, and monitor APIs from a single interface
- Production-ready deployment with HTTP endpoints
- Storage-agnostic design for flexible data storage choices
How to Use Fleak
- Start by creating a new workflow and add nodes for data intake and transformation.
- Configure nodes to call AI models, generate embeddings, and interact with databases or vector stores.
- Test the workflow, preview results, and refine as needed.
- Version the workflow, push to staging or production, and expose APIs via HTTP endpoints.
- Monitor performance and data accuracy from the built-in dashboards.
Safety and Governance (Guidance)
- Use Fleak to build production-grade data pipelines with clear versioning and change management.
- Ensure appropriate access controls and data privacy practices when connecting to sensitive data sources.
Example Workflows
- Real-time Slack history chatbot with embedded data from vector stores
- Product recommendations tailored to user data and external signals
- RAG-enabled LLM responses using Pinecone for retrieval
Pricing & Access (from the provided context)
- Try Free and Request a Demo options available
- Use Cases, Templates, and a catalog of integrations and partners
About Fleak
A platform designed for data teams to collaborate on AI transformations over API endpoints, combining ease of use with scalable, production-ready deployments. It emphasizes low-code orchestration, serverless deployment, and broad integration capabilities to simplify complex AI workflows.