Image In Words
Open siteImage Generation & Editing
Introduction
Generative model for ultra-detailed text from images
Image In Words Product Information
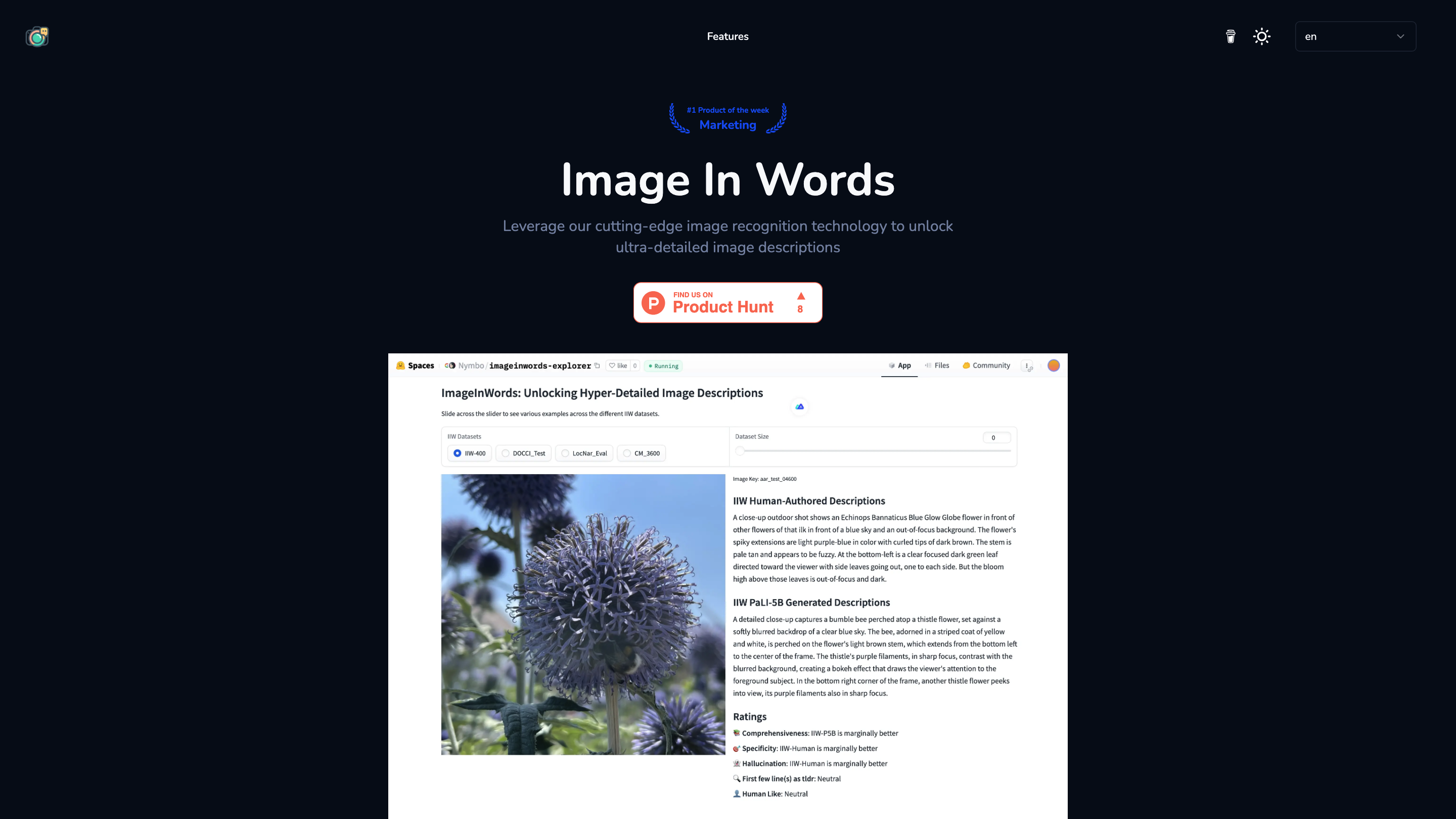
Image In Words is an AI-powered tool that unlocks ultra-detailed text descriptions from images using cutting-edge image recognition and vision-language modeling. It is designed to support scenarios requiring precise, human-involved image descriptions, particularly for assisting LLM assistants and enhancing AI recognition capabilities in complex tasks using GPT-4o. The service primarily supports English and is trained on a large English corpus to deliver high-quality, natural-sounding descriptions.
Overview
- Purpose: Generate ultra-detailed, accurate image descriptions to improve accessibility, search, and content understanding.
- Focus: Vision-language reasoning, high-detail narration, and reduction of fictional content in descriptions.
- Language: English (support for other languages listed in the interface, but core output is English).
- Data & Licensing: Model improvements and datasets (IIW) released under CC-BY-4.0; open-source data and benchmarks available via GitHub and Hugging Face.
How It Works
- Analyze the input image using advanced image recognition and vision-language models.
- Generate a comprehensive textual description that captures objects, actions, contexts, relationships, attributes, and scene details.
- Apply verification techniques to minimize non-existent or fictional details, ensuring factual accuracy.
- Present readable, coherent descriptions suitable for broad audiences and downstream applications.
Features
- Ultra-detailed image descriptions generated from images with high factual accuracy
- Vision-language reasoning improvements yielding coherent, context-aware narration
- Reduction of fictional content via rigorous verification
- Readability and comprehensiveness across diverse image content
- Enhanced applicability for accessibility, image search, and content review
- Models trained with IIW data for improved description quality and reasoning
- Open data and benchmarks released (CC-BY-4.0) for reproducibility and further research
Key Benefits
- Accessibility: Helps visually impaired users by providing rich, descriptive captions.
- Search and discovery: Enables better image indexing and retrieval through detailed descriptions.
- Content analysis: Facilitates more accurate review and annotation of visual content in various domains.
- Research and development: Offers high-quality, verifiable data and descriptions for vision-language model tuning.
Use Cases
- Generating captions for images in apps and websites
- Assisting LLMs with visual context to improve task performance
- Creating detailed datasets for training vision-language models
- Verifying image content description accuracy in QA and summarization tasks
Getting Started
- Access the Image In Words interface from the AI Tools platform.
- Upload an image and receive a detailed textual description in English.
- Review and utilize the description for accessibility, indexing, or downstream tasks.
Privacy and Safety
- Descriptions are generated from the provided image data; no unnecessary personal data is introduced.
- Content accuracy is prioritized, with measures to minimize fabrication in descriptions.
Related Resources
- IIW (Image In Words) IIW Benchmark datasets and descriptions
- CC-BY-4.0 licensed datasets and code on GitHub and Hugging Face
Core Features
- Ultra-detailed image descriptions
- High quality, coherent vision-language reasoning
- Verification to reduce fictional content
- Accessibility-friendly outputs
- Open datasets and benchmarks under CC-BY-4.0