LakeSail
Open siteCoding & Development
Introduction
Open-source Rust framework for Big Data and AI workloads
LakeSail Product Information
Big Data Processing for the AI Era — LakeSail
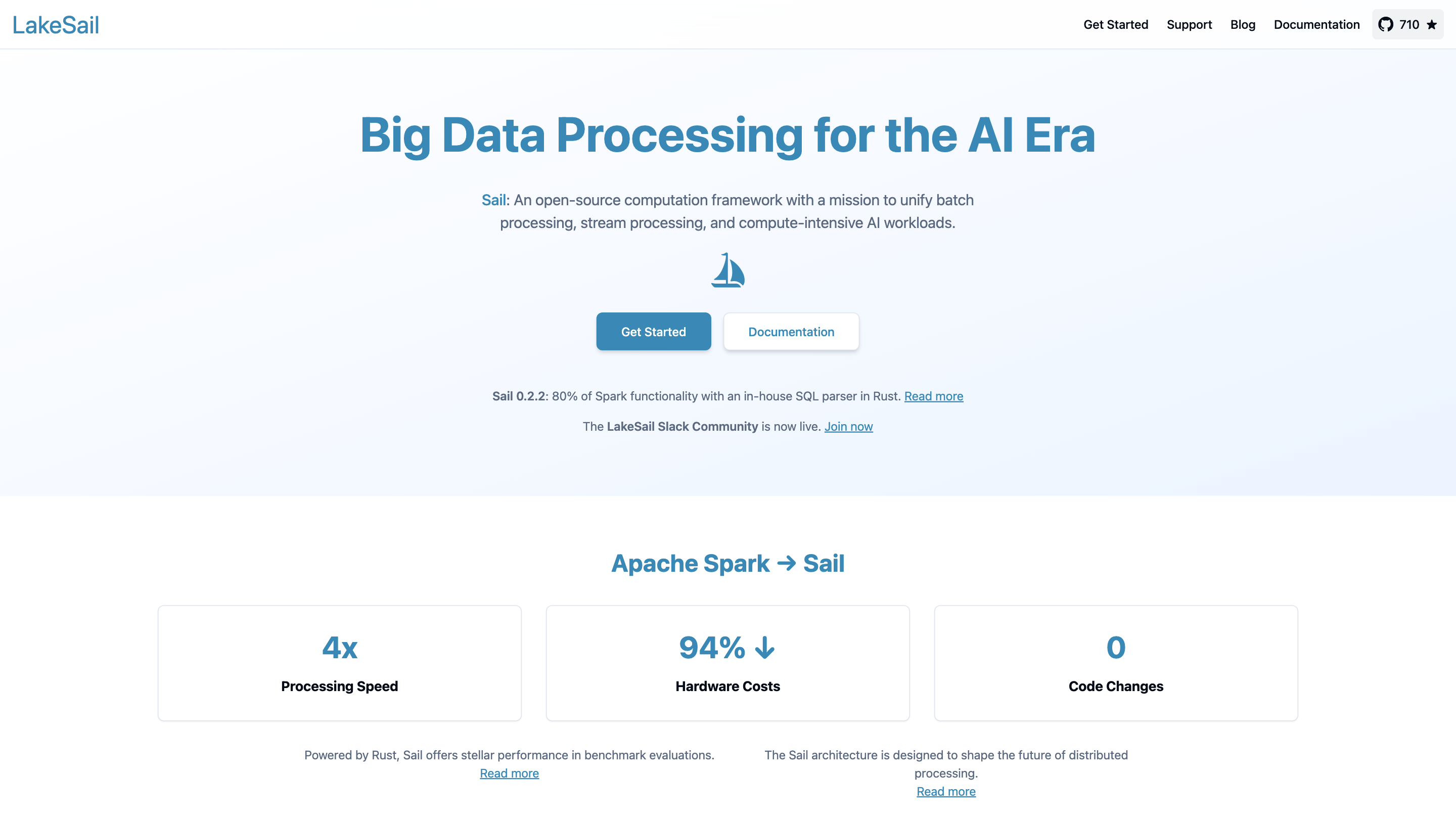
LakeSail is an open-source computation framework designed to unify batch processing, stream processing, and compute-intensive AI workloads. It provides a drop-in replacement for Apache Spark SQL and the Spark DataFrame API in both single-host and distributed environments, enabling fast, efficient data processing with minimal code changes.
Overview
- LakeSail (Sail) aims to accelerate data processing tasks while reducing hardware costs and preserving ease of use. It achieves 4x processing speed improvements and 0 additional code changes in benchmark evaluations, powered by a Rust-based in-house SQL parser and architecture designed to optimize performance.
- Sail offers compatibility with Spark SQL and the Spark DataFrame API, allowing users to run existing Spark workflows with minimal disruption.
- It provides tooling and guidance to get started, including installation commands, server setup, and examples of connecting PySpark to a Sail-backed SQL engine.
Get Started
- Install options include a Python package: pip install "pysail[spark]" alongside command-line tools for Sail.
- Run a Sail server locally or in a cluster (e.g., Kubernetes) and connect to it from PySpark without modifying existing PySpark code.
Example setup snippets:
- CLI installation and server start
- bash
- pip install "pysail[spark]"
- sail spark server --port 50051
- Connecting PySpark to Sail
- python
- from pyspark.sql import SparkSession
- spark = SparkSession.builder.remote("sc://localhost:50051").getOrCreate()
- spark.sql("SELECT 1 + 1").show()
- Kubernetes deployment
- bash
- kubectl apply -f sail.yaml
- kubectl -n sail port-forward service/sail-spark-server 50051:50051
Architecture and Capabilities
- Sail is designed to shape the future of distributed data processing with a focus on performance, scalability, and ease of integration.
- It provides a drop-in replacement for Spark SQL and the DataFrame API, enabling seamless migration from Spark-based workloads.
- The architecture supports both single-host and distributed deployment models.
Features
- Drop-in replacement for Spark SQL and Spark DataFrame API
- High performance with Rust-based SQL parsing and optimization
- Compatibility with PySpark with no code changes required
- Supports both batch and streaming workloads (unified processing)
- Kubernetes-ready deployment options for scalable environments
- PyPI and CLI tooling for easy installation and operation
- Commercial support options available with flexible coverage
How It Works
- Install Sail and run a Sail server.
- Connect your existing PySpark code to the Sail server using the sc://localhost:50051 URL.
- Execute SQL and DataFrame operations; Sail handles execution planning and distributed computation under the hood.
Support and Community
- LakeSail offers commercial support with various options tailored to user needs.
- Community resources include a public issue tracker and public Slack channel; enterprise plans provide private issue tracking and dedicated channels with guaranteed response times.
Safety and Legal Considerations
- Use Sail in compliance with its license and terms of service. Refer to official documentation for deployment best practices, security configurations, and data governance.
Core Information
- Name: Sail (LakeSail)
- Purpose: Unify batch, stream, and AI workloads with a Spark-compatible interface
- Language and Runtime: Rust-based core; Python (PySpark) integration
- Deployment: Single-host or distributed; Kubernetes support
- Licensing: Open source with commercial support options