Multimodal Model Evaluator
Open siteResearch & Data Analysis
Introduction
Model evaluation and sharing made simple.
Multimodal Model Evaluator Product Information
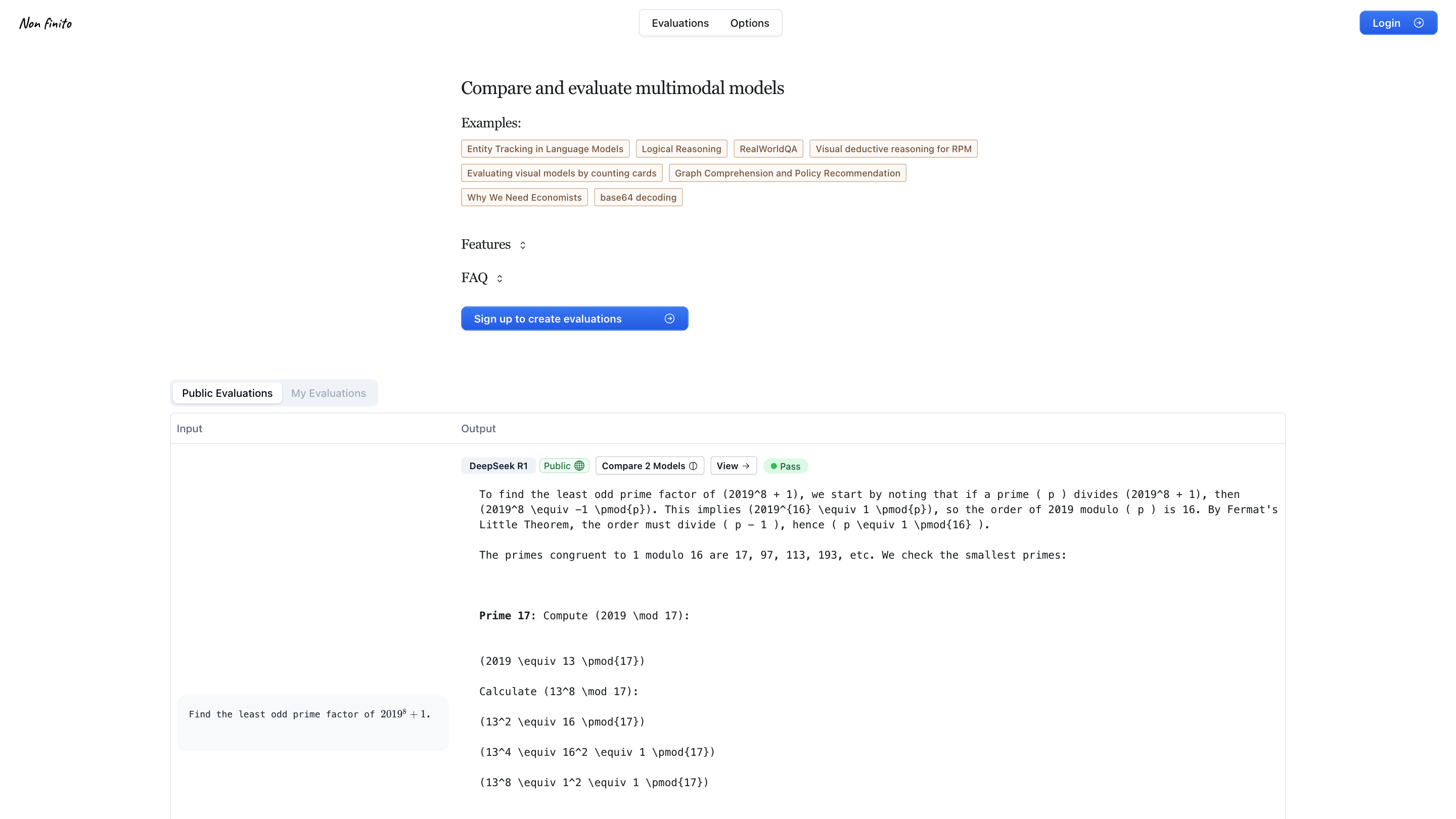
Evaluations - Non finito is an AI evaluation platform designed to compare and evaluate multimodal models across a variety of tasks. It appears to support interactive features such as toggles, sign-in for creating evaluations, public evaluations, and a gallery of model comparisons. The platform aggregates model outputs to help users assess performance on diverse problem types, including reasoning, visual understanding, math, and real-world QA.
How to Use Evaluations - Non finito
- Access the Evaluation Portal: Open the platform to view available models and evaluations.
- Choose a Model to Compare: Select from listed models (e.g., DeepSeek, OpenAI variants, Qwen, Q/GPT series, etc.).
- Run or View Evaluations: Inspect example tasks and model outputs, or run new evaluations if you have an account.
- Review Results: See Pass/Fail indicators, model comments, and differences in outputs across tasks.
- Save or Share: Use account features to save evaluations, generate reports, or share results publicly or with collaborators.
Core Capabilities
- Multimodal model evaluation: supports text, image, and mixed inputs.
- Model comparison: side-by-side analysis of multiple models on the same tasks.
- Public and private evaluations: toggle visibility and collaboration options.
- Input/Output capture: observe how models respond to given prompts and datasets.
- Example tasks across domains: arithmetic reasoning, visual reasoning, real-world QA, and more.
How It Works
- Users select tasks and models, then submit inputs to generate outputs. The platform collects results, enabling comparisons of accuracy, reasoning quality, and consistency across modalities.
- Tasks may include standard QA, algorithmic reasoning, image-based questions, and multi-step problem solving.
Safety and Ethical Considerations
- Ensure evaluations respect data privacy and copyright. Use public, non-sensitive prompts when sharing results.
- Clearly indicate when outputs are AI-generated and avoid misrepresentation.
Core Features
- Public and private evaluations
- Model comparison dashboards
- Support for multimodal tasks (text, images, and combinations)
- Input/Output capture and analysis across models
- Task libraries with diverse problem types
- Sign-up required to create and save evaluations