Orquesta
Open siteIntroduction
Orquesta is a collaboration platform that enhances SaaS with LLM capabilities.
Orquesta Product Information
Orq.ai is a Generative AI Collaboration Platform that helps product teams build, deploy, and manage large language model (LLM) powered applications at scale. It provides an end-to-end solution to control GenAI, orchestrate prompts, evaluate models, and monitor performance across the entire AI development lifecycle.
Overview
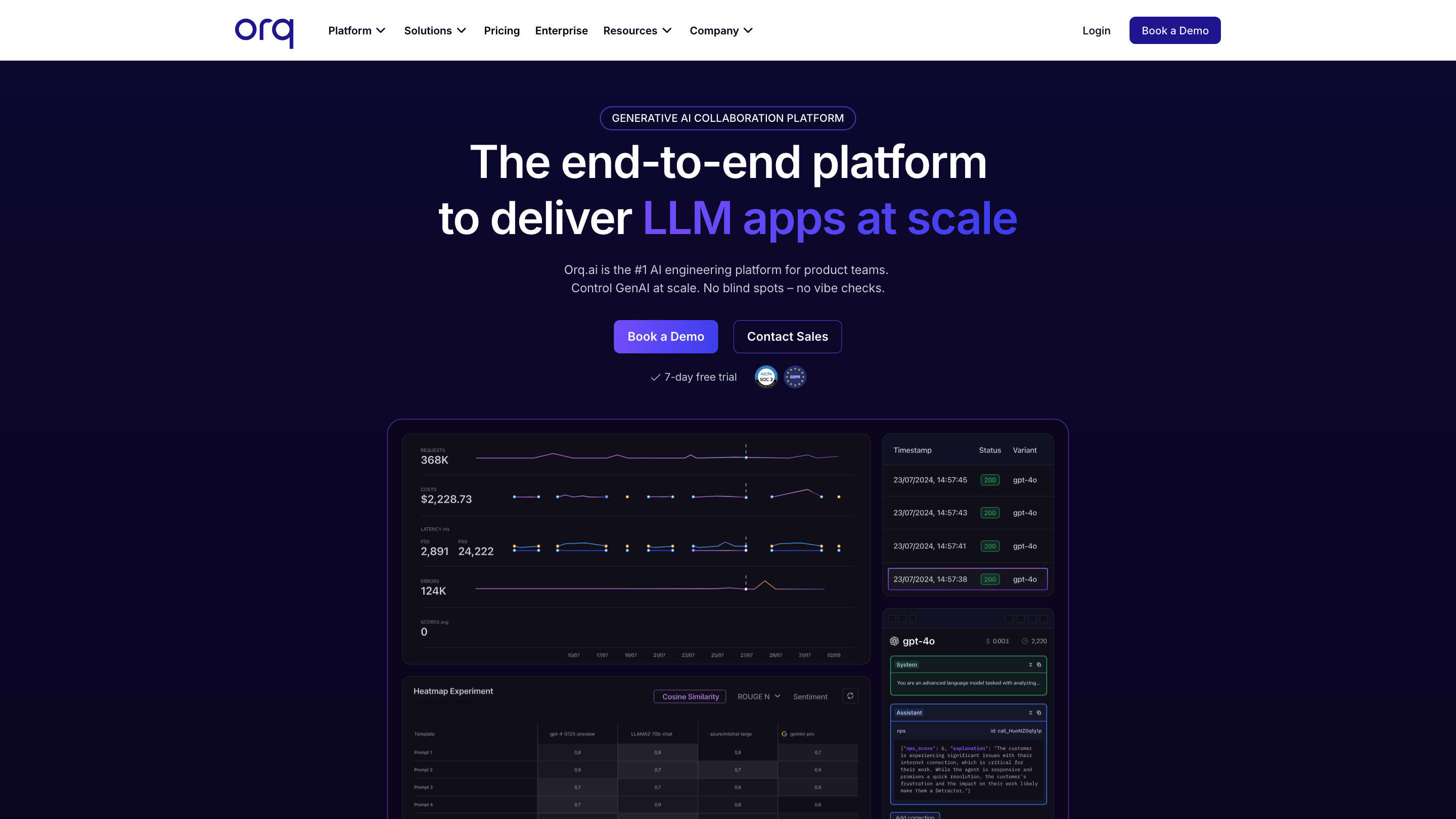
Orq.ai offers a unified platform to manage the lifecycle of LLM apps from prototype to production. It emphasizes collaboration across non-technical and technical roles, enabling teams to experiment, engineer prompts, deploy robust AI solutions, and observe costs, latency, and output in real time. The platform highlights ease of use, enterprise-grade security, and centralized control over multiple model providers and prompts.
How It Works
- End-to-end tooling to scale LLM apps: from prompt engineering to deployment and observability.
- SDK & API access: seamless LLM orchestration with one line of code and support for Node and Python SDKs.
- Centralized governance: AI Gateway connects 150+ AI models and enables contextualized routing and privacy controls.
- Observability & tracing: track cost, latency, throughput, and output to optimize performance.
- Experimentation: compare models and prompts at scale before moving to production.
- RAG (Retrieval-Augmented Generation): contextualize LLMs with private knowledge bases.
- Prompt management: decouple prompts from code, manage iterative workflows, and reuse prompts across apps.
Key Capabilities
- End-to-end platform to manage GenAI lifecycles
- Prompt engineering and management with decoupled prompts from code
- LLM orchestration via SDKs and a unified API gateway
- Evaluation and experiments to measure performance at scale
- LLM Observability for cost, latency, and output insights
- Tracing to debug complex pipelines
- RAG for private knowledge integration
- AI Gateway to connect multiple model providers or bring-your-own-models
- Case studies and best-practices to accelerate time-to-market
How to Use Orq.ai
- Assess and prototype: Use the Evaluator Library and Experiments to compare prompts and models.
- Engineer prompts: Use Prompt Engineering tools to design and iterate prompts, independently from code.
- Deploy: Move from prototype to production with end-to-end tooling and deployments.
- Observe & optimize: Monitor cost, latency, and quality with LLM Observability and Traces.
- Govern & scale: Route requests via AI Gateway and manage private data with privacy controls.
Use Cases
- Accelerating time-to-market for AI-powered SaaS
- Collaborative prompt engineering across cross-functional teams
- Managing large families of prompts and multiple LLMs at scale
- Observability-driven optimization of GenAI workloads
Product Modules
- End-to-end lifecycle tooling for LLM apps
- Prompt management: decouple prompts from code and manage iterative workflows
- LLM orchestration with Node and Python SDKs
- AI Gateway: access 150+ AI models or bring your own
- Experiments: compare LLMs and prompts at scale
- Evaluation: built-in evaluators to measure performance
- Traces: track events in LLM pipelines for debugging
- RAG: private knowledge bases for improved accuracy
- LLM Observability: cost, latency, and output monitoring
- Cost management and performance insights
- User-friendly collaborative UI for cross-functional teams
Safety and Compliance
- Enterprise-grade security with data governance and privacy controls
- Centralized management to reduce risk and ensure consistent policy enforcement
Core Features
- End-to-end platform to manage the AI development lifecycle in one place
- Collaborative UI enabling non-technical team members to participate in prompt engineering
- Time-to-market acceleration for GenAI-powered solutions
- Enterprise-ready security and data governance
- API and SDK access for developers (Node, Python) and one unified AI Gateway
- Evaluations, experiments, and observability to optimize models and prompts
- Tracing and debugging tools for complex LLM pipelines
- RAG integration with private data sources