Pinecone
Open siteIntroduction
Pinecone is a fast vector database for searching similar items in milliseconds.
Pinecone Product Information
Pinecone: The Vector Database for Scalable, Knowledgeable AI
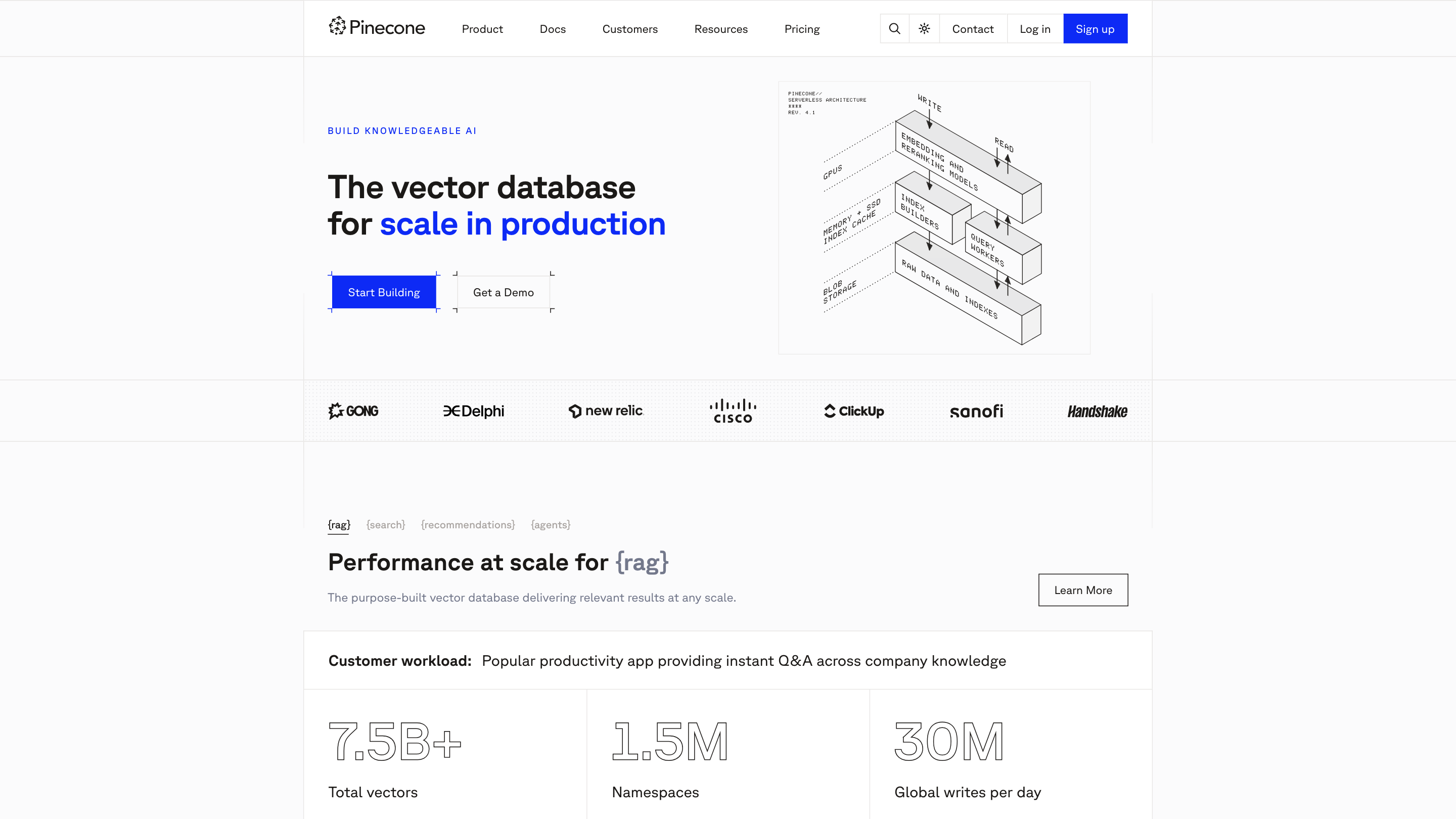
Pinecone is a purpose-built vector database designed to deliver relevant results at any scale, enabling production-grade knowledge retrieval, search, and recommendations. It is a hosted, serverless solution that simplifies scaling, indexing, and querying large vector datasets for applications such as RAG (retrieval-augmented generation), semantic search, and personalized recommendations.
Key strengths include rapid setup, serverless scaling, robust reliability, and extensive integrations with popular cloud providers, models, and frameworks. Pinecone emphasizes security, compliance, and observability to support enterprise-grade AI workloads.
Use Cases
- Recommendations: Powers personalized suggestions and job matches with precise vector-based matching.
- Search: Enables accurate semantic search across dynamic datasets, including billions of vectors.
- RAG (Retrieval-Augmented Generation): Facilitates retrieval of relevant documents to augment LLM outputs.
How It Works
- Create a vector index (namespace-based partitions for multi-tenant isolation).
- Ingest and upsert vectors (including metadata for filtering).
- Query with a vector to retrieve top_k most similar items, optionally filtered by metadata.
- Rerank results for additional precision.
- Use hosted models or bring-your-own vectors; supports full-text and semantic search toggles.
Core Capabilities
- Fully managed, serverless vector database with automatic scaling
- Fast setup: launch vector databases in seconds
- Real-time indexing: upserts and updates reflected instantly in reads
- Embeddings compatibility: use hosted models or your own vectors
- Optimized recall: high-quality results with low latency
- Fine-grained filtering: metadata filters to constrain results
- Reranking: additional precision on top results
- Namespaces: partition data for tenant isolation
- Integrations: works with major cloud providers, data sources, models, and frameworks
- Security and compliance: encryption at rest/in transit, private networking, SOC 2, GDPR, ISO 27001, HIPAA
- Observability and SLAs: uptime and support commitments for enterprise workloads
How to Use Pinecone (Quickstart Example)
- Create an index for your vector data (e.g., semantic-search).
- Ingest vectors with optional metadata under a namespace (e.g., breaking-news).
- Query by providing a vector, include filters if needed, and fetch top_k results.
- (Optional) Rerank results to boost relevance.
- Iterate and scale as your dataset grows.
Example (pseudo-code):
- Initialize Pinecone client with API key
- Select index and namespace
- index.query(vector=[...], filter={...}, top_k=3)
Why Pinecone for Your AI Workflows
- Scale: handle billions of vectors with serverless reliability
- Relevance: optimized recall and reranking for precise results
- Speed: rapid setup and low-latency retrieval
- Flexibility: hosted models or bring-your-own embeddings
- Security and Compliance: enterprise-grade protections and certifications
- Ecosystem: broad integrations across cloud providers and AI tooling
Core Features
- Fully managed, serverless vector database
- Rapid, scalable indexing and real-time upserts
- Support for hosted models or custom embeddings
- Advanced retrieval: top_k search with metadata filtering
- Reranking for enhanced result precision
- Namespaces for tenant isolation
- Wide range of integrations and deployment options
- Enterprise security and compliance (encryption, private networking, SOC 2, GDPR, ISO 27001, HIPAA)
- Observability, SLAs, and support for mission-critical applications