Pongo
Open siteResearch & Data Analysis
Introduction
Reduce LLM hallucinations by 80%
Pongo Product Information
Moondream: Open Source Vision-Language Model (VLM) Playground and Lineup
Moondream is an open-source, multimodal vision-language model (VLM) designed to run across diverse environments including servers, PCs, and mobile devices. The project emphasizes small, fast models with practical vision capabilities, quantization options, and accessibility for experimentation and deployment. Key variants include 2B and 0.5B parameter models, with support for FP16, int8, and int4 quantization, as well as quantization-aware training. The models are licensed under Apache 2.0, and Moondream promotes wide compatibility and easy integration for CPU and GPU inference.
How to Use Moondream
- Install or obtain a downloaded model file (examples show moondream-2b-int8.mf).
- Initialize the model in your environment (Python examples use the moondream package).
- Load an image and run a query or captioning task, such as asking questions about the image or generating detailed scene descriptions.
- Retrieve results (e.g., answers, captions, or detections) and use them in your application.
Examples showcased in the project include:
- Visual question answering (e.g., Is this a hot dog?)
- Caption generation for scenes (detailed underwater clownfish scene, etc.)
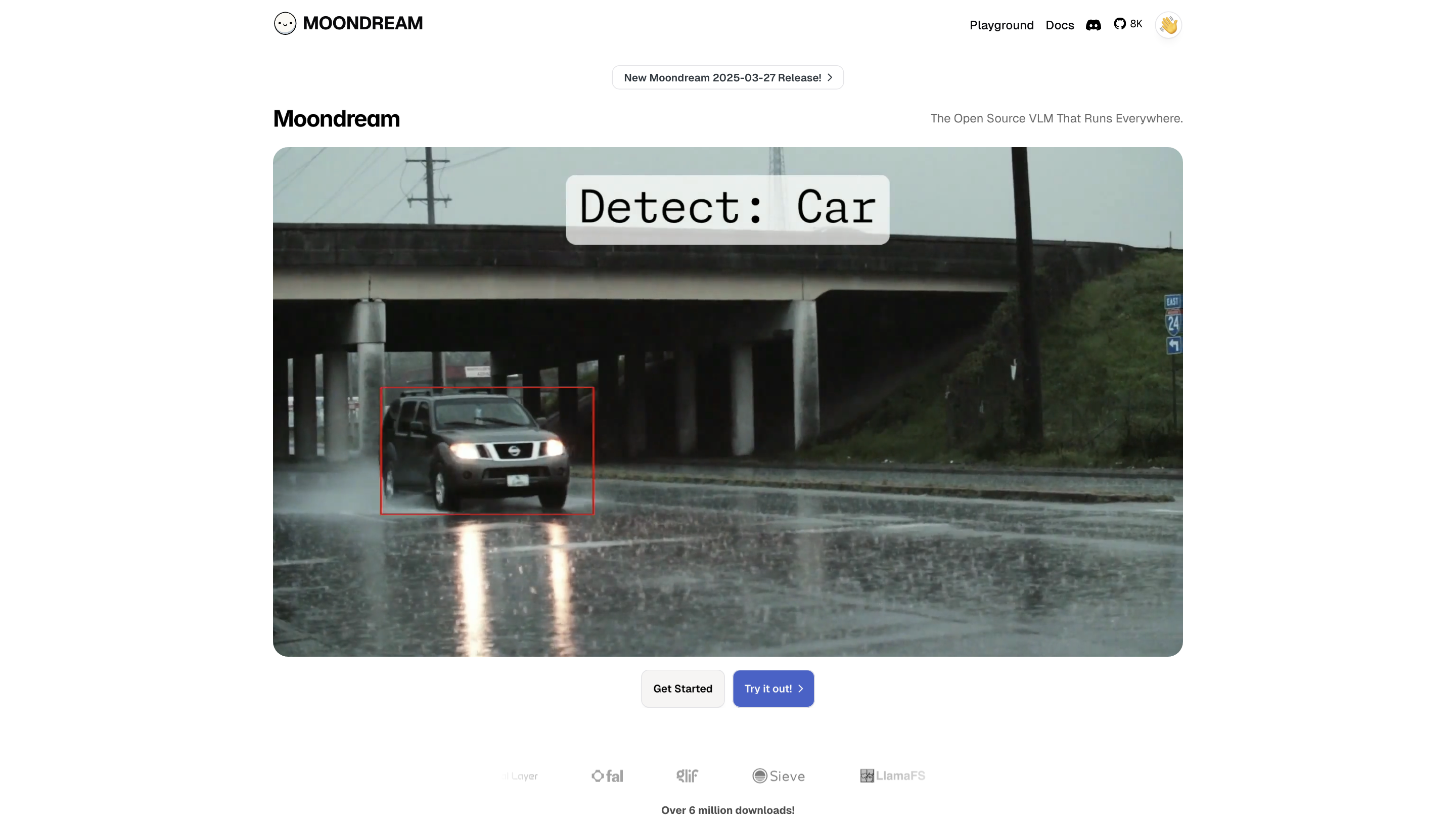
- Object detection and localization (bounding boxes and X/Y coordinates)
Moondream Lineup and Capabilities
- Moondream 2B: Powerful and fast, 1.9B parameters, FP16, INT8, INT4 quantized; 2 GiB memory; GPU/CPU-optimized inference; suitable for broader capabilities with smaller footprint.
- Moondream 0.5B: Tiny and speedy, 0.5B parameters, INT8/INT4 quantized; 1 GiB memory; mobile/edge target devices; GPU/CPU-optimized inference.
- Quantization and Quantized Aware Training across models to balance accuracy and efficiency.
- Target devices include servers, PC, and mobile; emphasis on CPU and GPU inference performance across environments.
- Licensing: Apache 2.0 for all shown variants and components.
How It Works (Overview)
- Moondream provides vision-language capabilities via an open-source multimodal LLM framework.
- The models are designed to be lightweight yet capable of understanding visual input and generating human-like responses, captions, and detections.
- Users can perform prompts that blend image understanding with natural language tasks (e.g., Q&A, captioning, description, procedural prompts).
- The project highlights strong community reception with positive feedback about speed, size, and performance relative to larger models.
Safety and Ethical Considerations
- As with any multimodal model, use should respect privacy and consent when analyzing images containing people or sensitive content.
- Ensure compliance with licensing terms and attribution where required by the Apache 2.0 license.
Core Features
- Open-source multimodal LLM (vision-language model) that runs on servers, PCs, and mobile devices
- Multiple model sizes: 2B and 0.5B parameters with quantization (FP16, INT8, INT4)
- Quantization-aware training support for improved efficiency
- CPU- and GPU-optimized inference across target devices
- Lightweight footprint suitable for edge/mobile deployments
- Apache 2.0 licensed components
- Simple example workflows for image queries, captions, and object localization
- Quick-start guidance and sample code for loading models and querying images
Example Workflows
- Load a downloaded model (e.g., moondream-2b-int8.mf)
- Open an image and run prompts such as:
- Query: "Is this a hot dog?"
- Caption: Generate a detailed description of the scene
- Object detection: Obtain bounding boxes and coordinate points
- Integrate results into applications requiring visual understanding and natural language outputs
Target Audience
- Developers seeking a small, fast, open-source VLM for vision-language tasks
- Researchers prototyping multimodal capabilities in lightweight environments
- Edge and mobile applications requiring efficient inference without heavy GPU resources
Licensing
- Apache 2.0 License for Moondream components
Quick Start Snippet (conceptual)
- pip install moondream
- from moondream import vl
- model = vl(model="./moondream-2b-int8.mf")
- from PIL import Image
- image = Image.open("./image.jpg")
- result = model.query(image, "Is this a hot dog?")
- print("Answer:", result["answer"])