Reworkd AI
Open siteResearch & Data Analysis
Introduction
AI Agents for web data extraction.
Reworkd AI Product Information
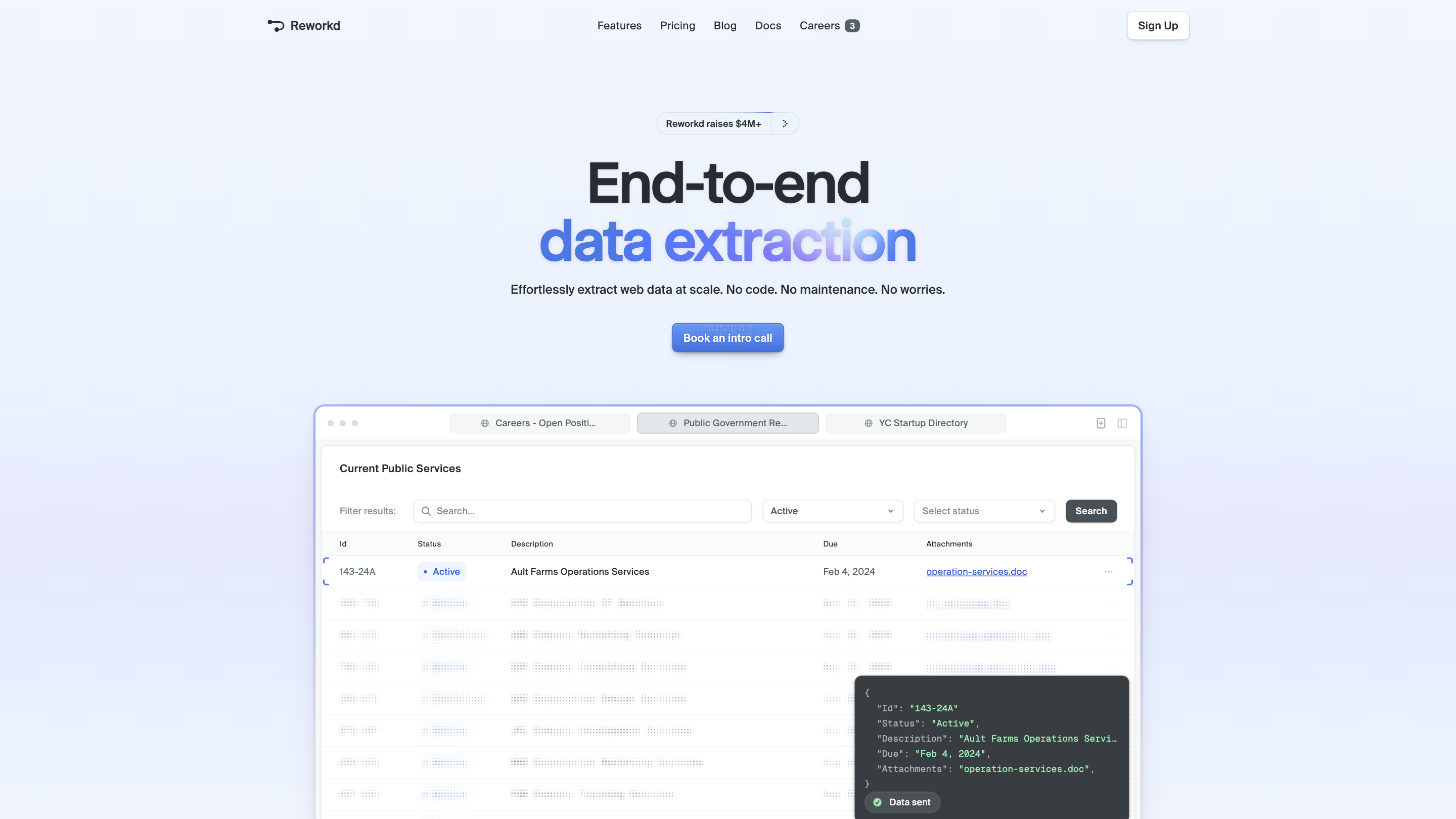
Reworkd / Reworkd AI Web Data Extraction Tool is an end-to-end data extraction platform that automates the entire web data pipeline—from crawling and code generation to extraction, validation, and delivery—without requiring manual coding or maintenance. It is designed to scale across hundreds or thousands of sites, handling dynamic content, pagination, and rate limits, while offering self-healing capabilities and detailed analytics to monitor extraction health.
How it works
- Scan and generate code: Reworkd crawls target websites and automatically generates extraction code tailored to your data requirements.
- Run extractors & validate: The system executes the extractors, validates results, and ensures data reliability.
- Output data: Export data in the formats you need, while the system handles retries, proxies, and robustness.
- Self-healing scrapers: When website content changes, Reworkd detects the changes and repairs the data pipeline without manual intervention.
Why choose Reworkd
- Save time by eliminating hand-written scraping scripts and infrastructure.
- Reduce costs associated with data scraping expertise and engineering effort.
- Minimize operational hassle with built-in proxy management, headless browser concerns, and data consistency checks.
- Gain visibility into extraction health via analytics and dashboards.
Use Cases
- Large-scale web data collection across numerous sites
- Regularly updated data such as regulations, pricing, job postings, or product data
- Data pipelines requiring minimal maintenance and quick iteration
How to Use Reworkd
- Define target sites and data points.
- Let Reworkd auto-generate extractors.
- Run extractions and review analytics to ensure data quality.
- Export data to your data lake or downstream systems.
Data & Privacy Considerations
- Designed for business data extraction workflows.
- Ensure compliance with site terms of service and applicable laws when pulling data.
Features
- End-to-end data extraction pipeline (crawl -> code generation -> extract -> validate -> output)
- No-code/low-code approach: automatic code generation for extractions
- Self-healing scrapers that repair data failures and adapt to site changes
- Automated handling of pagination, dynamic content, and rate limits
- Automated retries, proxy management, and headless browser concerns handled
- Interactive analytics dashboard to monitor extraction success, failures, and performance
- Multi-format data export and integration with downstream systems
- Teams section with open positions and career opportunities
- Deep analytics and operation metrics (succeeded, running, pending, failed)
Safety & Compliance
- Use in compliance with site terms and applicable laws; monitor data usage and ensure privacy protections where required.
Company / Contact
- Backed by notable founders and YC-affiliated expertise; emphasis on automation and reducing data infrastructure burden.