UltiHash
Open siteOther
Introduction
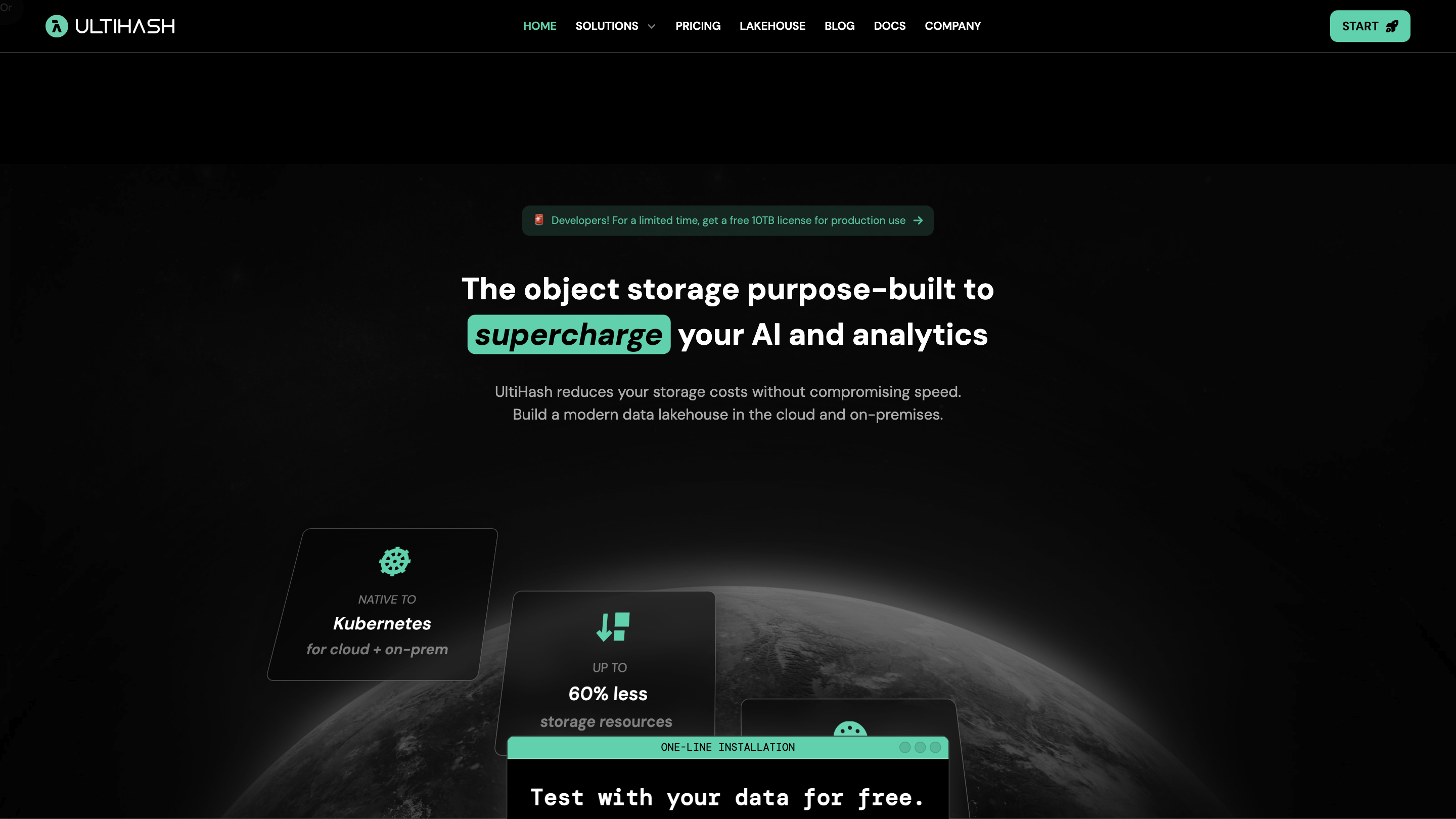
High-performance object storage for AI and analytics.
UltiHash Product Information
UltiHash: The Object Storage for AI + Analytics
UltiHash is an object storage platform purpose-built to supercharge AI and analytics workloads. It combines a modern data lakehouse-friendly foundation with Kubernetes-native deployment, S3-compatible APIs, and advanced data-management features to deliver high throughput, cost-efficient storage for AI data and large-scale analytics.
How UltiHash Helps
- Reduces storage costs by enabling byte-level deduplication and efficient data management across AI and analytics datasets.
- Speeds up data access with high-throughput architecture suitable for AI training, inference, and real-time analytics.
- Provides flexible deployment across cloud, on-premises, or hybrid environments via Kubernetes.
- Integrates with common data processing and analytics tools through an S3-compatible API, plus open table formats (Iceberg, Delta Lake, Hudi).
- Supports policy-based access management and data resiliency features to meet governance and reliability needs.
Key Use Cases
- Generative AI data pipelines and large language model (LLM) workflows
- Retrieval-Augmented Generation (RAG) data stores for AI apps
- Computer vision, self-driving vehicle data, and sensor data for AI/ML workloads
- Global speech-to-text and other AI-powered data processing pipelines
- High-throughput analytics and data lakehouse architectures
How It Works
- Object storage with a Kubernetes-native architecture that can run cloud, on-premises, or hybrid.
- S3-compatible API for easy integration with processing engines (Python, Airflow, Spark, Flink, Kafka, Trino, Presto).
- Metadata-aware storage layer that supports open table formats (Iceberg, Delta Lake, Hudi) for lakehouse-style querying.
- Byte-level deduplication to minimize redundant data and reduce overall storage footprint (up to 60% reduction noted in materials).
- Efficient, scalable deletion with reference accounting to reclaim space immediately when fragments are no longer used.
- Erasure coding (Reed-Solomon) for data resiliency (coming soon) to guard against data loss.
- Policy-based access management to enforce granular data access controls.
Architecture Highlights
- S3-compatible API for broad compatibility and easy migration.
- Kubernetes-native deployment for cloud, on-prem, and hybrid setups.
- High-throughput design optimized for AI/ML and analytics workloads without adding compute overhead from deduplication.
- On-demand, scalable storage that supports petabytes and beyond with flexible storage classes.
Security & Compliance
- Built-in access management with granular policies to control who can access which datasets.
- Data sovereignty and governance features aligned with enterprise requirements.
- High-throughput, efficient operations to minimize exposure windows during data management tasks.
Industry Use Cases
- Generative AI + LLM data storage and processing
- RAG-based AI applications requiring fast, scalable data retrieval
- AI-ready data lakehouse environments with open table format support
- Self-driving vehicle data and large-scale computer vision datasets
- Global speech-to-text and other AI-enabled content processing workflows
Tech Stack & Capabilities
- Object storage with Kubernetes-native deployment
- S3-compatible API for compatibility with tools like Python, Airflow, Spark, Flink, Kafka, Trino, Presto
- Metadata layer supporting Iceberg, Delta Lake, and Hudi
- Byte-level deduplication to reduce storage needs
- Efficient delete operations with immediate space reclamation
- Erasure coding for data resiliency (Coming Soon)
- Policy-based access management for granular security
- High-throughput architecture optimized for AI + analytics workloads
Start Today
- Cloud/on-prem/hybrid deployment options with Kubernetes
- No-signup required for evaluation in some configurations (varies by deployment)
- Learn more about storage savings, integration, and security from UltiHash whitepapers and docs
Safety and Legal Considerations
- UltiHash emphasizes data security, privacy, and governance; ensure appropriate access controls and compliance with internal policies and external regulations when storing sensitive data.
Core Features
- Kubernetes-native deployment across cloud, on-prem, and hybrid environments
- S3-compatible API for easy integration with processing and analytics tools
- High-throughput object storage optimized for AI + analytics workloads
- Byte-level deduplication to reduce total storage footprint (up to ~60% reduction)
- Open table format support (Iceberg, Delta Lake, Hudi) for lakehouse analytics
- Efficient, immediate space reclamation on data deletion
- Policy-based access management for granular data security
- Scalable, resilient storage designed for AI data pipelines