ClearGPT
Open siteCoding & Development
Introduction
Secure and customizable enterprise-grade platform for tailored LLMs and generative AI.
ClearGPT Product Information
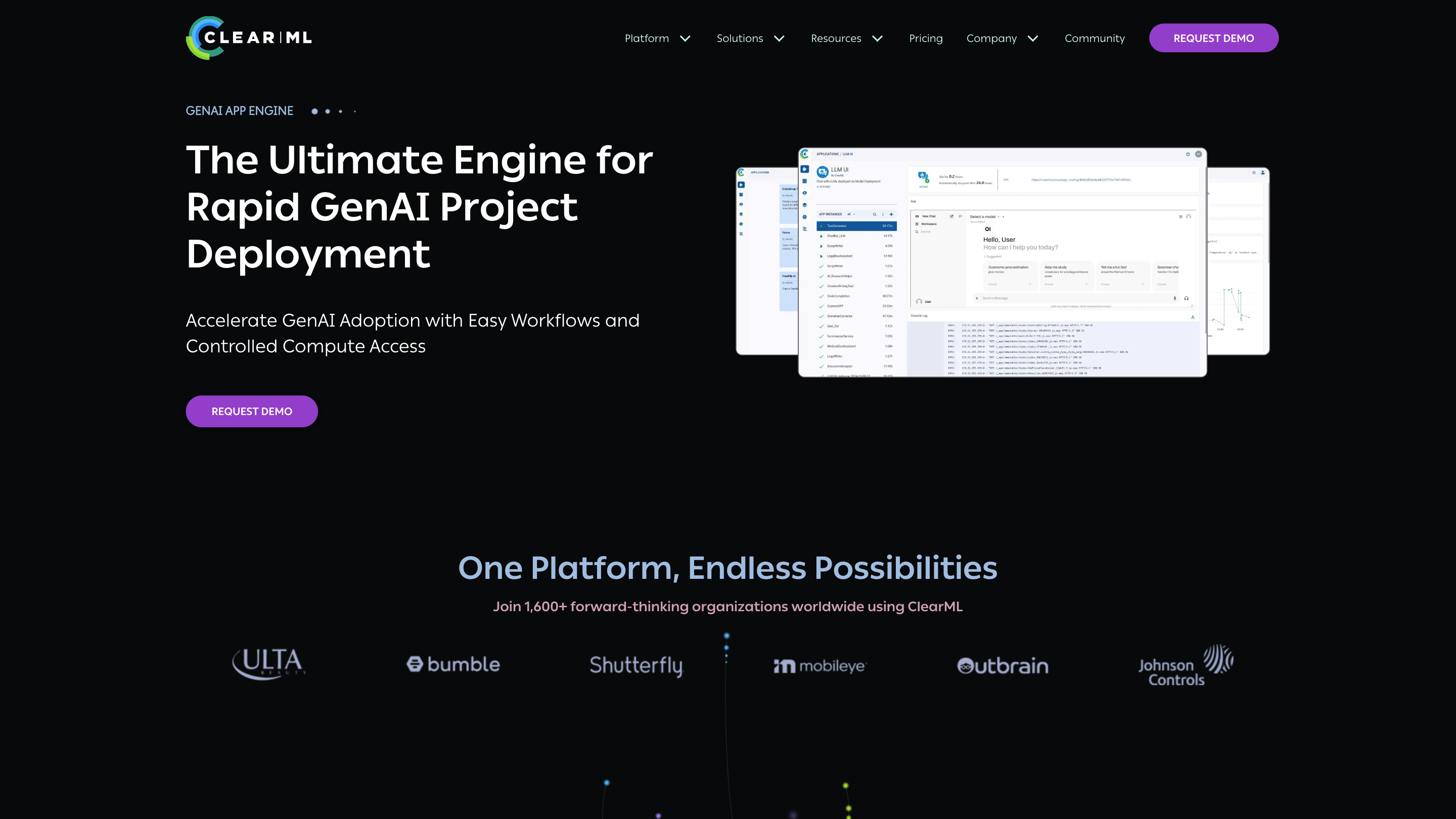
GENAI APP ENGINE by ClearML is the Ultimate Engine for rapid GenAI project deployment. It provides an infrastructure control plane to manage compute access, usage, performance monitoring, and security, enabling developers to deploy LLMs on top of a scalable platform. Users can run off-the-shelf LLMs or bring their own fine-tuned models, accelerate testing, and deploy GenAI apps into production faster.
Overview
- One platform to launch GenAI apps with streamlined tooling and orchestration
- Supports plugging in custom or fine-tuned models (e.g., from Hugging Face)
- Integrates LLM serving engines like vLLM, Llama.cpp, Triton, and more
- Provides secure API endpoints with RBAC and networking controls
- Dynamic resource allocation and traffic routing to optimize performance and cost
- Built for enterprises: governance, security, and scalable deployment across teams
How it Works
- Deploy Any LLM with a Single Click
- Connect a custom or fine-tuned model and launch a GenAI app via UI or CLI
- Choose from supported serving engines (vLLM, Llama.cpp, Triton, etc.)
- Manage Resources and Access
- Allocate resources for models, teams, and business units
- Role-based access control (RBAC) and secure networking
- Monitor Performance & Usage
- Endpoint monitoring for traffic, latency, memory, CPU/GPUs, I/O, and network
- Observability for all AI API endpoints
- Optimize Availability & Cost
- Horizontal scaling of inference to handle peak demand
- Unified memory approach to minimize GPU usage and keep apps “always on”
- Launch Custom GenAI Apps
- Build wizards and customize UIs for internal users
- Rapidly deploy end-user-facing GenAI applications
- Gain Visibility on AI Agents
- Create and track AI agents; monitor usage and performance
Use Cases
- Enterprise GenAI app deployment and management
- Rapid testing and iteration of LLMs and prompts
- Secure, scalable GenAI services across departments
- On-demand scaling to meet fluctuating workloads
How It Works (Technical Details)
- Infrastructure control plane handles authentication, traffic routing, and resource management
- Deploy endpoints or apps that can host general or domain-specific GenAI models
- RBAC and authentication protect data, models, and APIs
- Dynamic pipelines and apps enable data ingestion, cleansing, training, and vector databases for fine-tuning
Safety and Governance
- Centralized control plane with secure access and monitoring
- Designed for enterprise environments with security and compliance in mind
Core Features
- Single-click deployment of LLMs (custom or fine-tuned models)
- Support for multiple LLM serving engines (vLLM, Llama.cpp, Triton, etc.)
- Secure API endpoints with role-based access control (RBAC)
- Dynamic resource allocation across models, teams, and business units
- Horizontal scaling for inference to maintain availability during peak usage
- End-to-end monitoring of endpoints: requests, latency, memory, CPU/GPU, I/O, network
- Cost-efficient inference via unified memory and on-demand resource usage
- Build and deploy GenAI apps with customized user interfaces (UIs) and wizards
- Visibility and management of AI agents to optimize tasks
- Enterprise-ready governance, security, and collaboration across teams