Doctly.ai
Open siteIntroduction
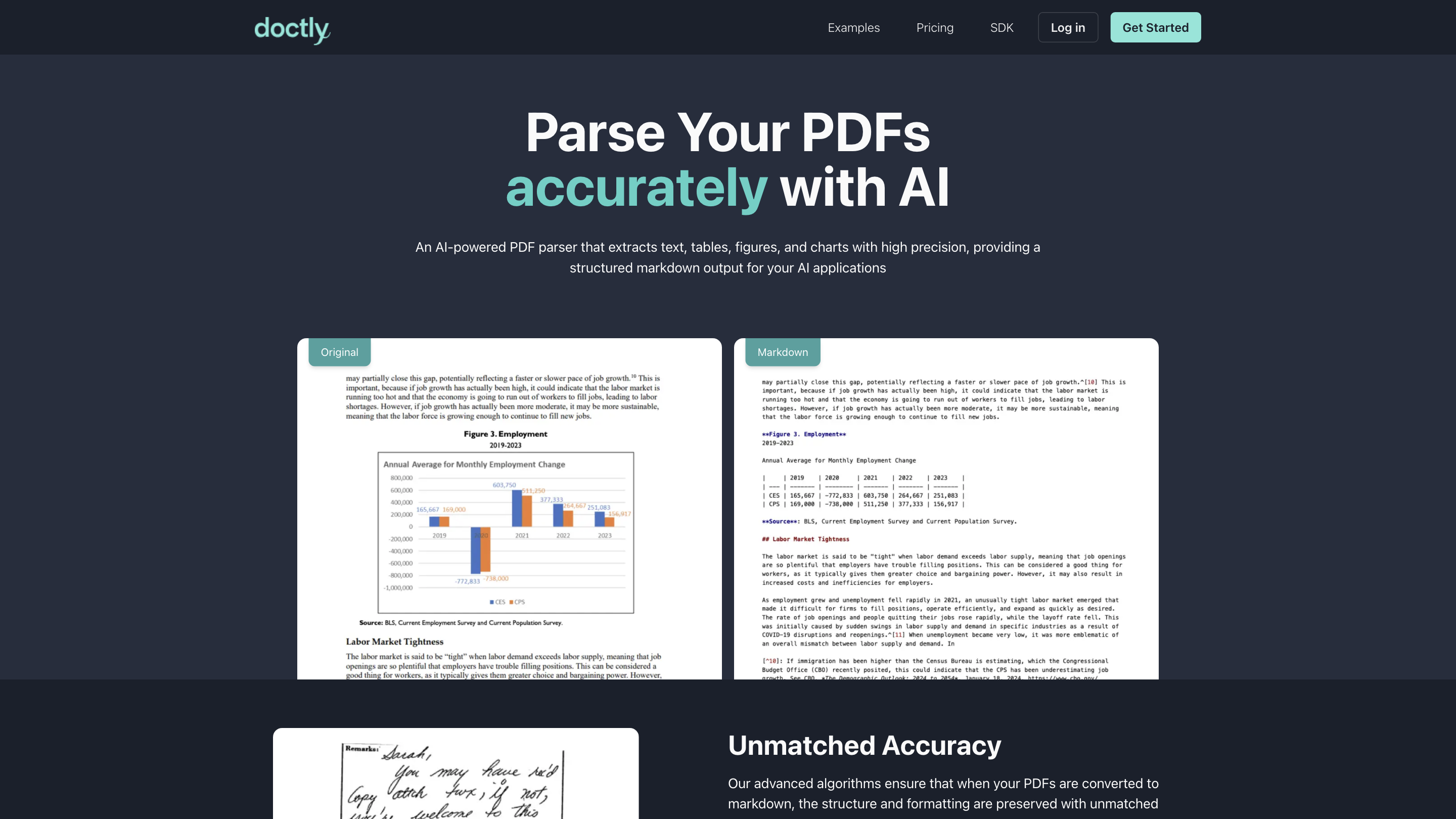
AI-powered PDF parser converting PDFs to structured markdown.
Doctly.ai Product Information
Doctly AI — AI-powered PDF Parser is a high-precision tool designed to parse PDFs into well-structured Markdown output suitable for AI applications. It preserves original formatting and structure, accurately extracts text, tables, figures, and charts, and supports custom data extraction workflows through dedicated API endpoints. The solution emphasizes unmatched accuracy, easy integration via REST APIs, and scalability for complex documents, including handwritten content.
How It Works
- Upload or point Doctly at your PDF document.
- Doctly processes the document to extract text, tables, figures, and charts with high precision.
- The output is a structured Markdown representation that retains original formatting for reliable downstream processing.
- If you need specific data, use custom data extraction workflows to tailor what information is extracted and how it is formatted. Each workflow has its own API endpoint for easy integration.
Key Capabilities
- High-precision extraction of text, tables, figures, and charts from PDFs
- Preservation of original content and formatting in Markdown output
- Handling of complex documents and handwritten text with unmatched accuracy
- Custom workflow data extraction with dedicated API endpoints
- Simple REST-based API for quick integration into existing workflows
- Examples and SDKs to accelerate integration (Python SDK and REST usage)
Getting Started
-
REST API: Integrate using standard HTTP requests and your API key.
-
Python SDK: Example usage to convert PDFs to Markdown:
-
import doctly
-
client = doctly.Client(api_key='YOUR_API_KEY')
-
content = client.process('path/to/your/file.pdf')
-
Get started for free to evaluate accuracy and integration effort.
Features
- Unmatched accuracy: preserves structure and formatting for reliable downstream use
- Extracts text, tables, figures, and charts with high precision
- Handles complex documents and handwritten text
- Custom data extraction workflows with dedicated API endpoints
- REST-based API for rapid integration
- Python SDK example and easy-to-follow integration steps
- Scalable and easy to incorporate into existing workflows
Use Cases
- Transform PDFs to structured Markdown for AI agents and data pipelines
- Extract financial data, scientific measurements, or specialized information via custom workflows
- Replace messy, unstructured PDFs with clean, process-ready Markdown content
Pricing & Access
- Free starter access available to test core capabilities
- Custom data extraction workflows available via dedicated API endpoints (book a demo to explore)
Safety & Compliance
- Ensure proper licensing and permission for processed documents
- Handle sensitive data in accordance with your organization’s data governance policies
Core Features
- Accurate PDF to Markdown conversion preserving content and formatting
- Structured output suitable for AI applications and downstream processing
- Customizable data extraction via dedicated workflow endpoints
- REST API and Python SDK for quick integration
- Scalable solution capable of handling complex and handwritten documents