Elixir
Open siteCoding & Development
Introduction
Automated testing and call review platform for AI voice agents.
Elixir Product Information
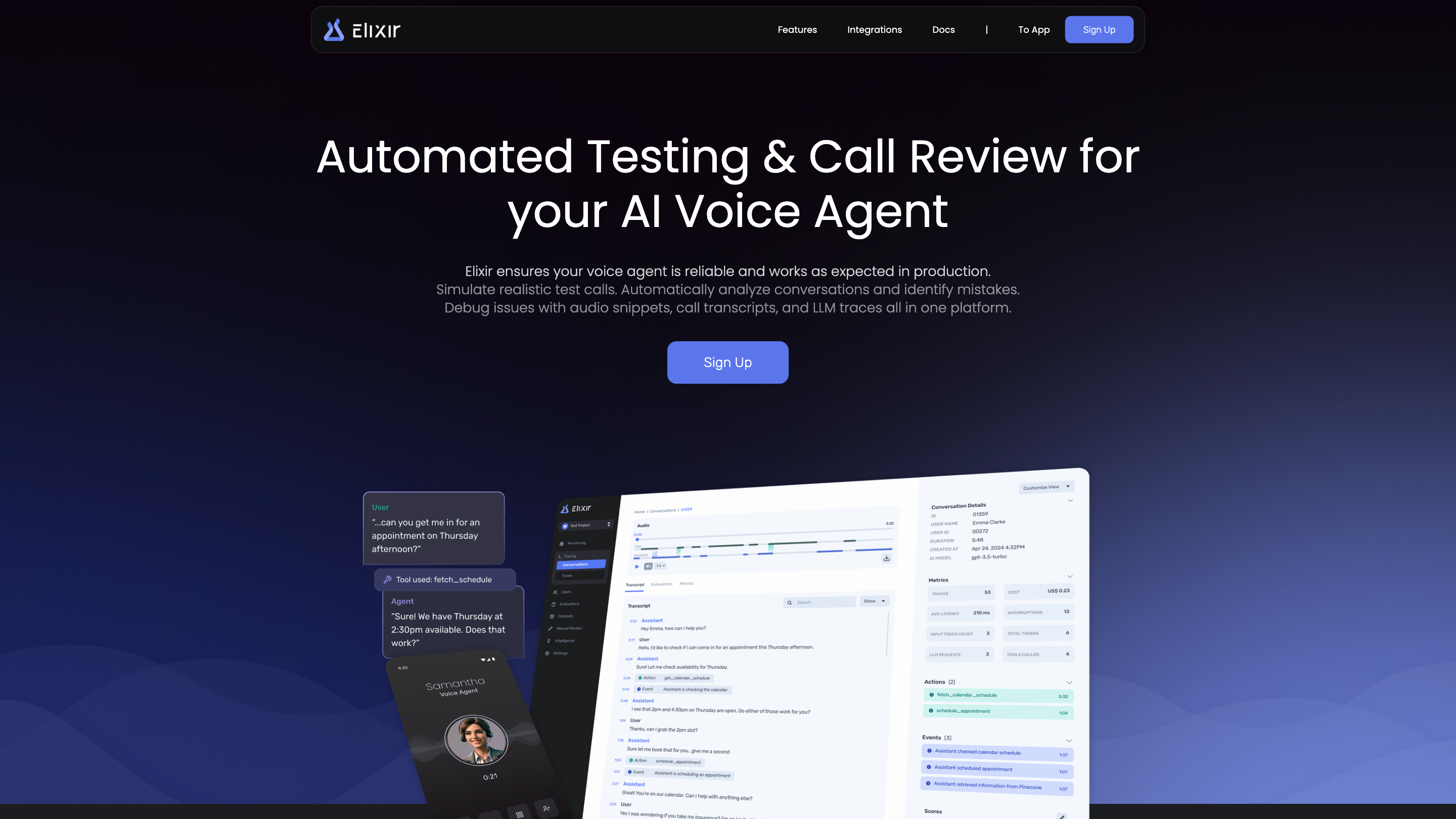
Elixir Observability is an AI-powered observability platform designed for multimodal, audio-first experiences. It helps you monitor, trace, test, and improve the performance of voice agents by analyzing conversations, auto-grading, and providing human-in-the-loop feedback. The platform supports automated testing, real-time monitoring, detailed traces, and dataset tools to simulate and refine agent behavior. It is designed for teams building reliable voice-first products and integrates with common AI stacks and telephony interfaces.
Key Capabilities
- Monitoring & Analytics: Track call metrics, identify mistakes at scale, measure agent performance (interruptions, transcription errors, tool calls, user frustrations), and spot patterns between agent mistakes and user behavior. Set thresholds and receive Slack alerts for critical concerns.
- Tracing: Debug issues quickly with audio snippets, LLM traces, and transcripts. Access detailed traces for complex abstractions (RAG, Tools, Chains, etc.). Play back audio to review user–agent dialogue and pinpoint bottlenecks.
- Score & Review: Auto-grade calls against a configurable rubric, triage conversations to manual review queues, and provide human-in-the-loop feedback to improve auto-scoring accuracy.
- Testing & Simulation: Simulate thousands of calls for full test coverage, configure language, accents, pauses, and tone to test agents in realistic scenarios. Run auto-tests on significant changes. Train testing agents on real conversation data to mimic users.
- Dataset & Iteration: Test agents on comprehensive scenario datasets, save edge cases, and simulate new prompt iterations before deploying. Use datasets for fine-tuning, few-shot, or prompt improvements.
- Integrations: Compatible with your AI stack, including LLM providers, vector DBs, frameworks, telephony & WebRTC, transcription & voice LLM providers, and more.
How It Works
- Monitor core metrics and identify mistakes at scale with out-of-the-box metrics.
- Generate detailed traces from audio snippets, transcripts, and LLM traces to diagnose issues.
- Auto-grade conversations using defined success criteria and route “bad” conversations to human reviewers.
- Run large-scale automated tests and simulations to ensure reliability before deployment.
- Use datasets and prompts to continuously improve model performance and conversational quality.
Safety and Best Practices
- Use the platform to boost reliability and user experience for voice agents while maintaining proper governance and human-in-the-loop review where appropriate.
Contact & Access
- Email: [email protected] | [email protected]
- Website sections: Home, Features, Integrations, Docs, Sign Up
- Private beta availability with demo scheduling options
Core Features
- Monitoring & Analytics for scalable call metrics and real-time alerts
- Tracing with audio snippets, transcripts, and LLM traces
- Score & Review with auto-grading and manual review workflows
- Testing & Simulation of thousands of calls for full coverage
- Dataset management for scenario coverage and prompt iteration
- Integrations with LLM providers, vector databases, telephony/WebRTC, transcription services
- Cross-functional collaboration support via human-in-the-loop feedback