Graviti
Open siteResearch & Data Analysis
Introduction
Data platform for managing datasets, collaboration, and data versioning through MLflow.
Graviti Product Information
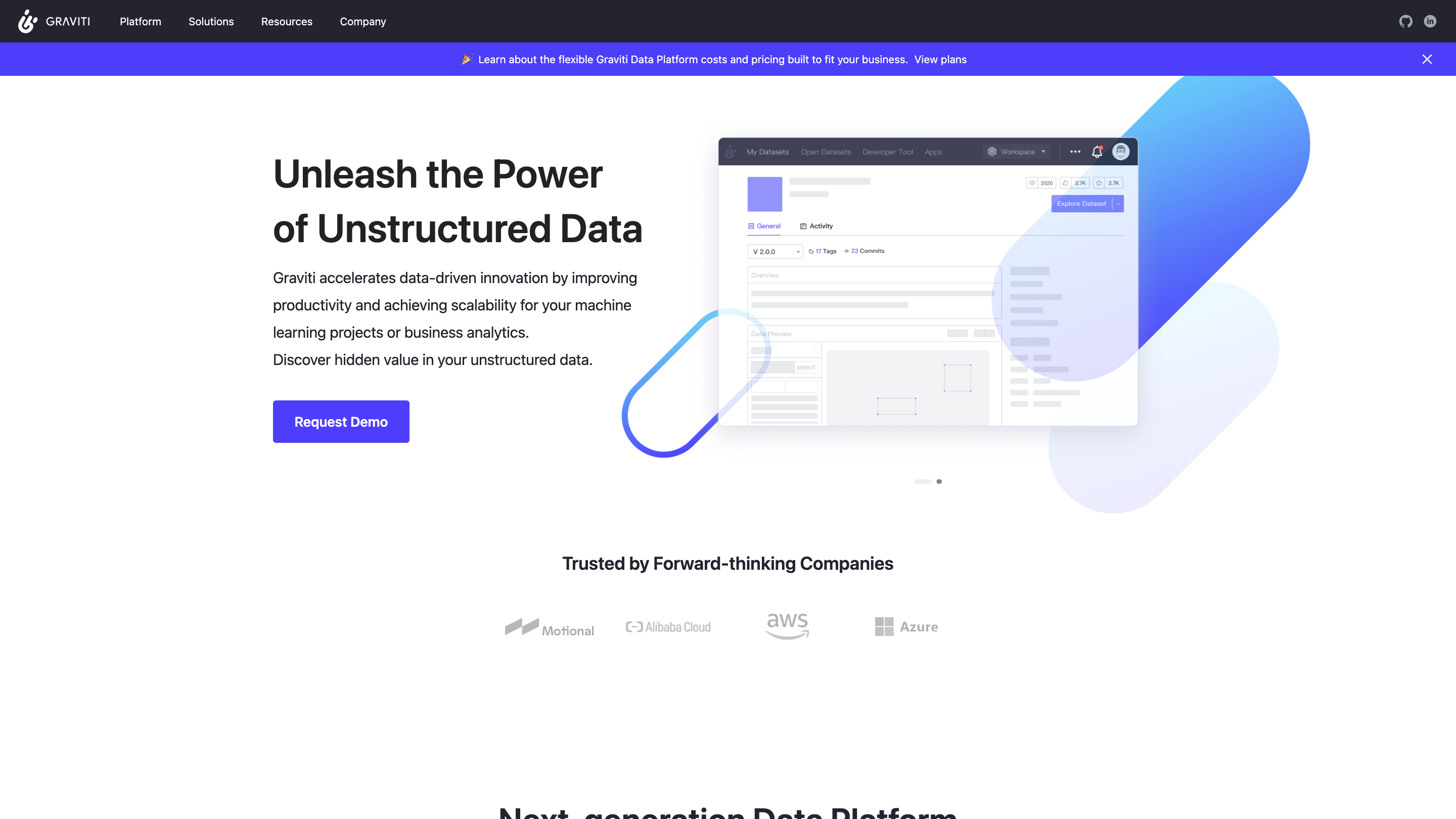
Graviti Data Platform
Graviti is a next-generation data platform designed to unlock the value of unstructured data at scale for analytics and AI. It helps data teams unify data, accelerate ML workflows, and derive actionable insights from complex data with a focus on curation, versioning, orchestration, and collaboration.
Overview
- Accelerates data-driven innovation by improving productivity and scalability for machine learning projects and business analytics.
- Enables use of unstructured data at scale, revealing hidden value across diverse data sources.
- Built to help organizations derive value from complex data, unify data teams, and speed up ML pipelines from data ingestion to model training.
How It Works
- Ingest and manage raw data, metadata, and semantic data in a single platform.
- Curate datasets efficiently using zero-copy data handling and customizable processing pipelines.
- Apply data versioning and lineage with a Git-like interface to track all changes and collaborations.
- Automate end-to-end data workflows with a visual workflow builder and scalable compute.
- Collaborate across teams on shared datasets without overlap or conflicts.
Key Capabilities
- Zero-copy data curation: Manage and curate raw, metadata, and semantic data in one place with efficient storage.
- Customizable querying and filtering: Filter and prepare data with flexible queries for downstream analytics and model training.
- Data version control and lineage: Git-like data versioning, branches, and lineage tracking to maintain reproducibility.
- Workflow automation: Build and automate data pipelines with a workflow builder and one-click processing.
- Large-scale compute: Process vast volumes of data with scalable compute resources.
- Data quality and imbalance management: Identify under-represented data and improve dataset quality.
- Data preprocessing automation: Automate preprocessing steps, including data augmentation and auto-labeling.
- Automated training setup: Trigger training pipelines automatically as new data arrives.
- Collaboration across teams: Work concurrently on the same datasets with conflict-free collaboration.
- Open data hosting: Host open datasets to accelerate experimentation and benchmarking.
How to Use Graviti
- Ingest and organize data: Upload raw data, metadata, and semantic annotations to centralize your data assets.
- Curate datasets: Use zero-copy tools to curate and prepare datasets for analytics or model training. Apply filters and transformations as needed.
- Version and track: Use the Git-like interface to create branches, commit changes, and view dataset lineage.
- Automate workflows: Build end-to-end pipelines with the workflow builder, enabling automated preprocessing and feature engineering.
- Collaborate: Invite teammates, coordinate on the same datasets, and monitor changes in real-time.
- Deploy and iterate: Launch training pipelines when new data arrives and visualize version differences to monitor progress.
Industry Solutions & Data Availability
- Supports hosting and collaborating on open datasets (e.g., nuScenes, MOTIONAL, BDD100K, UC Berkeley MNIST, Yann LeCun resources).
- Enables organizations to find, access, and reuse high-quality data for AI and analytics initiatives.
Why Graviti
- Save time and boost productivity: Reduce manual data prep and accelerate ML workflows.
- Scale with confidence: Handle large unstructured datasets with robust curation, versioning, and automation.
- Foster collaboration: Enable cross-team collaboration without data conflicts.
- Lower costs: Centralize data management and automate repetitive tasks.
Core Features
- Zero-copy data curation for raw, metadata, and semantic data
- Git-like data versioning with branches and lineage
- Visual workflow builder for automated data pipelines
- Large-scale, on-demand compute for data processing
- Data quality checks and imbalance detection
- Automated data preprocessing (augmentation, labeling, etc.)
- Automated training setup triggered by new data
- Collaborative multi-user data workspaces
- Open data hosting and access to open datasets