LastMile AI
Open siteIntroduction
Generative AI made easy for engineering teams.
Featured
Chatbase
Chatbase is an AI chatbot builder that uses your data to create a chatbot for your website.
Wan AI
Video & Image Generation Model from Alibaba Cloud
Dora Studio
Transform your ideas into stunning motion graphics
ElevenLabs
The voice of technology. Bringing the world's knowledge, stories and agents to life
LastMile AI Product Information
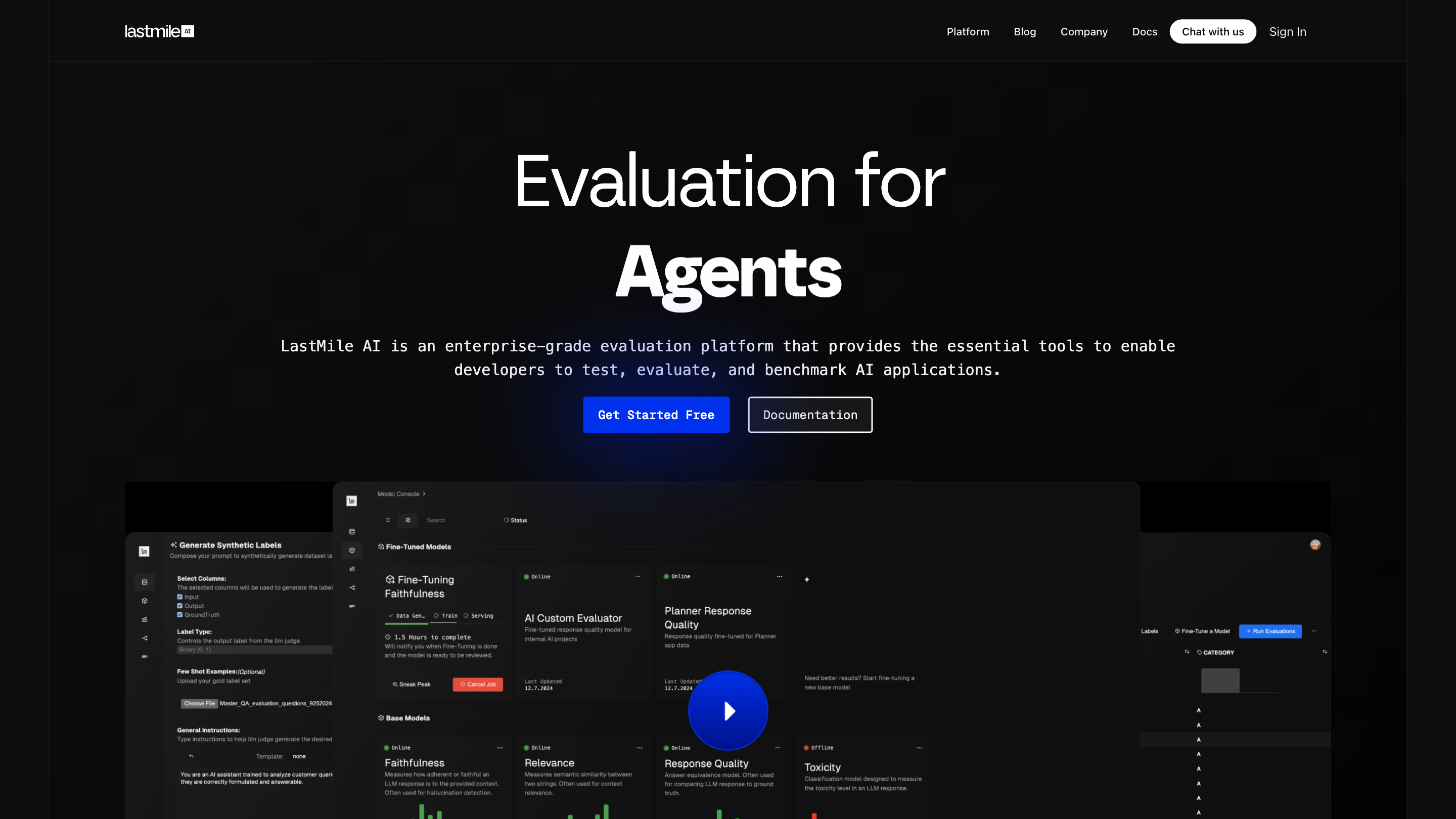
LastMile AI AutoEval — Generative AI Evaluation Platform is an enterprise-grade platform designed to help developers test, evaluate, and benchmark AI applications. It ships with battery-included evaluation metrics for RAG and multi-agent AI, along with fine-tuning capabilities to design custom evaluators. The platform emphasizes reproducibility, private deployment, and real-time evaluation at scale.
How it works
- Install and integrate: Quick-start with code examples for Python and TypeScript.
- Run evaluations: Use built-in metrics or your own custom evaluators to measure how well your AI system performs on real-world tasks.
- Fine-tune evaluators: Train evaluator models tailored to your data distribution and evaluation criteria.
- Deploy securely: Run AutoEval in Private Virtual Cloud or on your own infrastructure with robust data governance.
- Monitor in real time: Real-time inference, guardrails, and continuous monitoring for production-grade reliability.
Core Capabilities
- AutoEval Out-of-the-Box Metrics for RAG and multi-agent AI applications
- Fine-tuning service to design your own evaluators
- Real-time AI evaluation with blazing-fast inference
- Private deployment options (Private VPC / On-Prem) for data security and compliance
- Synthetic data generation to automate labeling and reduce manual effort
- Reproducible experiment management to accelerate innovation
- Custom metrics support to capture nuanced evaluation criteria
- Guardrails and proactive monitoring to detect anomalies and mitigate risks
- Cross-language client examples (Python and TypeScript) for easy integration
- Scalable evaluation runs and large-scale data support
How to Use AutoEval
-
Python example (pip install lastmile):
-
from lastmile.lib.auto_eval import AutoEval, BuiltinMetrics
-
client = AutoEval()
-
result = client.evaluate_data( data=pd.DataFrame({"input": ["Where did the author grow up?"], "output": ["France"], "ground_truth": ["England"]}), metrics=[BuiltinMetrics.FAITHFULNESS] )
-
TypeScript example:
-
const { AutoEval, BuiltinMetrics } = require("lastmile/lib/auto_eval");
-
const client = await AutoEval.create();
-
const result = await client.evaluateData({ data: [{ input: "Where did the author grow up?", output: "France", ground_truth: "England" }], metrics: [BuiltinMetrics.FAITHFULNESS] });
-
Custom metrics: Upload app data, define your own evaluator models, and fine-tune as needed.
Feature Highlights
- Out-of-the-Box metrics for evaluation of RAG and multi-agent systems
- Fine-tuning of evaluator models to align with app-specific criteria
- Real-time evaluation with ultra-low latency inference
- Private deployment options for data control and regulatory compliance
- Synthetic data generation to automate labeling and data creation
- Reproducible experiment management for reliable results
- Custom metrics and custom evaluator support for bespoke needs
- Guardrails and continuous monitoring to proactively manage risk
- Cross-language SDKs (Python and TypeScript) for seamless integration
- Scalable evaluation workflows with support for large datasets
Why Choose AutoEval
- Trustworthy, production-ready evaluation tooling designed for real-world AI systems
- End-to-end workflow from data generation to evaluation and monitoring
- Flexible deployment models to meet enterprise security, privacy, and compliance requirements
- Accelerates AI innovation by reducing manual labeling and accelerating experimentation
Safety and Deployment Considerations
- Deploy within your own private cloud or on-prem to maintain data sovereignty
- Use synthetic data generation to minimize exposure of sensitive information
- Implement guardrails to detect and mitigate risky model behaviors in production
Quick Start Resources
- Official documentation and API guides
- Examples and tutorials for AutoEval in Python and TypeScript
- Pricing tiers including no-cost entry for quick experimentation