Meteron AI
Open siteIntroduction
Meteron AI simplifies AI business growth with load-balancing, storage, and model agnostic capabilities.
Meteron AI Product Information
Meteron AI - Tools & Resources to Grow Your AI Business
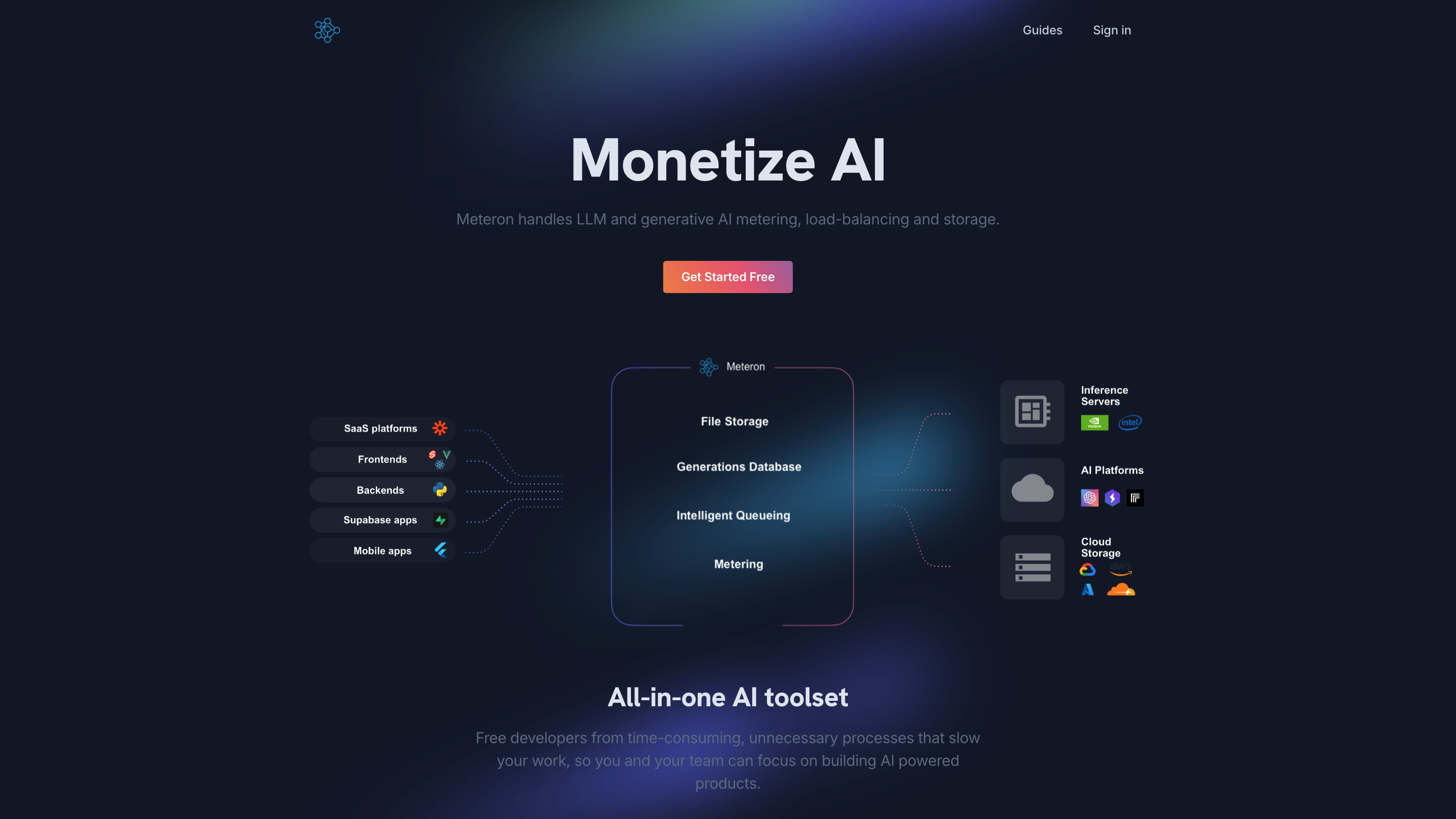
Meteron AI provides a comprehensive platform for metering, scaling, and storing AI workloads. It enables developers to build, deploy, and monetize AI-powered applications with flexible metering (per request or per token), elastic scaling, and unlimited cloud storage. It is designed to work with any model and to streamline the lifecycle of AI-powered products from development to production.
Overview
- All-in-one AI toolset to speed up development and reduce operational overhead.
- Centralized metering to charge users per request, per token, or both.
- Elastic queueing and load balancing across multiple servers to handle demand spikes.
- Unlimited cloud storage with support for major cloud providers.
- Compatibility with any model (e.g., Llama, Mistral, Stable Diffusion v1/v2, DALL-E, and others).
- Ready-to-use examples and a pathway to build and deploy AI apps quickly.
How Meteron Works
- Integrates with your AI model endpoints via a simple HTTP-based API.
- Applies per-user and per-request metering, token counting, and billing logic.
- Queues and load-balances requests across your servers to absorb spikes in demand.
- Provides cloud storage and data management for generated assets.
- Offers on-premise licensing if you prefer to host Meteron yourself.
Meteron also includes a flexible pricing model with tiered plans and a free tier, designed to accommodate startups to large teams. It supports per-user metering, credits, and a priority-based QoS system to differentiate VIP users from free users.
Use Cases
- Build AI applications that generate images, text, or other content while enforcing per-user limits.
- Monetize AI services by charging per request or per token.
- Scale AI workloads with elastic queueing and dynamic server provisioning.
- Centralize storage and access to generated assets across cloud providers.
- Deploy multi-tenant AI apps with per-tenant quotas and usage tracking.
Pricing Plans (High level)
- Free: $0 / mo
- Professional: $39 / mo
- Business: $199 / mo
Each plan includes a defined set of admins, storage, image generations, LLM chat completions, and features such as per-user metering, credit systems, elastic queues, and automatic load balancing. Details and updates are available on their pricing pages.
How to Integrate
- Use standard HTTP clients (curl, Python requests, JavaScript fetch) to call Meteron’s generation API.
- Define your servers and endpoints in the web UI or via API to dynamically update server lists.
- Implement per-user limits and headers (e.g., X-User) to enforce quotas.
- Choose priority classes (high, medium, low) to optimize fairness and latency for different user tiers.
Safety and Governance
- Meteron enforces usage limits and quotas to prevent abuse and to manage costs.
- On-prem licenses are available for customers with strict data residency or security requirements.
Core Features
- Per-request and per-token metering with flexible pricing.
- Elastic queueing and load balancing to handle traffic spikes.
- Unlimited cloud storage with multi-provider support.
- Compatibility with any AI model and endpoint.
- Multi-tenant support with per-user quotas and priority-based QoS.
- Server concurrency control and intelligent QoS for optimized throughput.
- Automatic retries (coming soon) and data export capabilities.
- On-prem deployment options for fully self-hosted setups.