Mixpeek
Open siteIntroduction
Mixpeek is an intelligent file store with powerful search capabilities.
Mixpeek Product Information
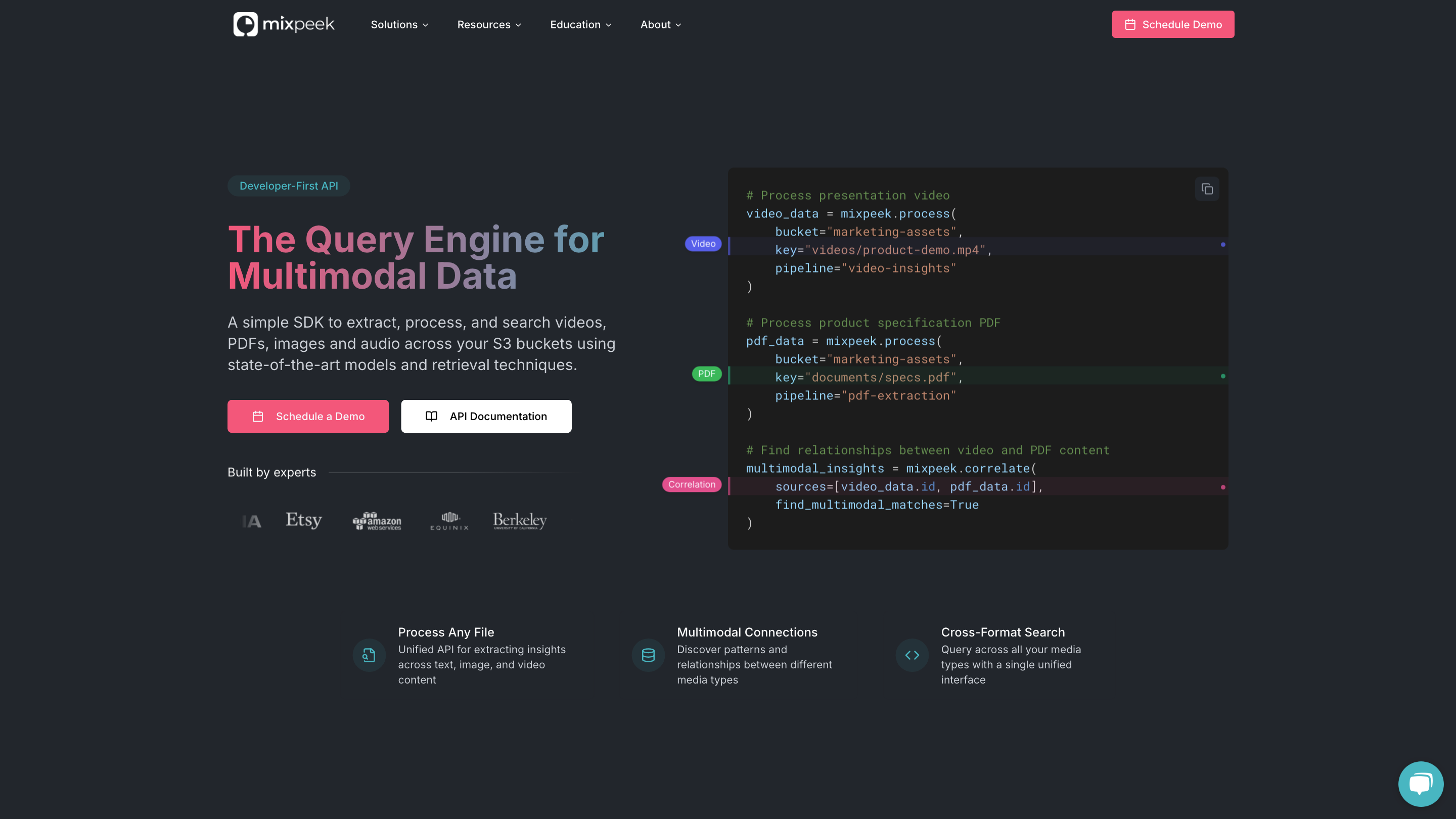
Mixpeek: The Multimodal Data Warehouse for Developers is a developer-first platform that provides a unified API to extract, process, and search content across text, image, video, audio, and PDF data stored in AWS S3. It enables cross-format search, multimodal feature extraction, and connections between media types to reveal relationships and insights that span documents, videos, and images. The platform emphasizes seamless ingestion, advanced retrieval techniques, and scalable infrastructure to power multimodal applications without heavy engineering overhead.
How Mixpeek Works
- Upload Objects: Ingest unstructured data from your sources to Mixpeek via S3 direct integration.
- Extract Features: Run specialized extractors to derive meaningful features from text, images, audio, video, and PDFs.
- Enrich Features: Normalize and enrich extracted data to enable powerful search and analytics.
- Build Retrievers: Create retrieval pipelines that leverage semantic and cross-format search across all media types.
You can perform cross-format queries across all media types with a single unified interface, enabling multimodal relationships and insights that would be difficult to discover with separate tools.
Core Capabilities
- Unified multimodal API: Process and search text, image, video, audio, and PDF content from S3 in one interface.
- Feature extractors for every data type: Text embeddings, named entity recognition, keyword extraction, topic modeling, language detection, sentiment analysis, image features, video insights, audio transcripts, and more.
- Cross-format search: Query across all media types and retrieve relevant results regardless of content form.
- Multimodal connections: Discover relationships and patterns between videos, PDFs, images, and transcripts.
- Semantic indexing and retrieval: Build optimized indices to support fast semantic search.
- Multilingual processing: Analyze content in multiple languages with detection, translation, and processing support.
- Model management and lifecycle: Manage embedding models and retrieval techniques with backward compatibility and seamless upgrades.
- No infrastructure burden: Scale automatically with traffic and only pay for active search operations.
Typical Workflows and Examples
- Process a video: mixpeek.process(bucket = "marketing-assets", key = "videos/product-demo.mp4", pipeline = "video-insights")
- Process a PDF: mixpeek.process(bucket = "marketing-assets", key = "documents/specs.pdf", pipeline = "pdf-extraction")
- Correlate media: multimodal_insights = mixpeek.correlate(sources = [video_data.id, pdf_data.id], find_multimodal_matches = True)
Sample feature outputs shown in the documentation include:
- Text Embedding: semantic embeddings for documents and transcripts
- Named Entity Recognition: extract people, organizations, locations
- Text Summarization and Sentiment Analysis: concise summaries and sentiment scores
- Keyword Extraction and Topic Modeling: key phrases and themes
- Language Detection and Multilingual Processing: identify language and handle multiple languages
- Quality of results: detailed fields such as original_length, summary, sentiment score, and confidence
How It Helps Your Organization
- Media & Entertainment: improve content discovery, tagging, and monetization across large video libraries.
- Retail & E-commerce: enable visual product search and asset tagging across catalogs.
- Advertising & Media: scalable analysis of millions of assets, brand safety checks, and faster insights.
- Education Technology: accelerate content organization and cross-format learning materials.
Security, Privacy, and Compliance
- Ingested data remains in your S3 buckets; Mixpeek provides a managed processing layer while respecting data locality.
- Access and permission controls follow your existing AWS setup; data processing is scoped to your pipelines.
- Best practices and governance for model updates and embedding versioning are supported to minimize risk during upgrades.
What You Get with Mixpeek
- Unified multimodal API for text, image, video, audio, and PDF processing
- Cross-format search across all media types with a single query interface
- Rich feature extractors for multiple data types (embeddings, NER, summarization, sentiment, keywords, topics, language detection, etc.)
- Multimodal relationships discovery and correlation across media
- Semantic indexing and fast retrieval with cross-model compatibility
- Multilingual processing and translation support
- Seamless model management, incremental updates, and backward compatibility
- Automatic ingestion from AWS S3 and multi-format support (PDFs, images, videos, audio)
- Observability: detailed logs, latency, throughput, and relevance metrics
- Pay-for-use pricing model with auto-scaling and no idle charges