PDFMerse
Open siteResearch & Data Analysis
Introduction
AI tool for extracting data from PDF to structured formats.
PDFMerse Product Information
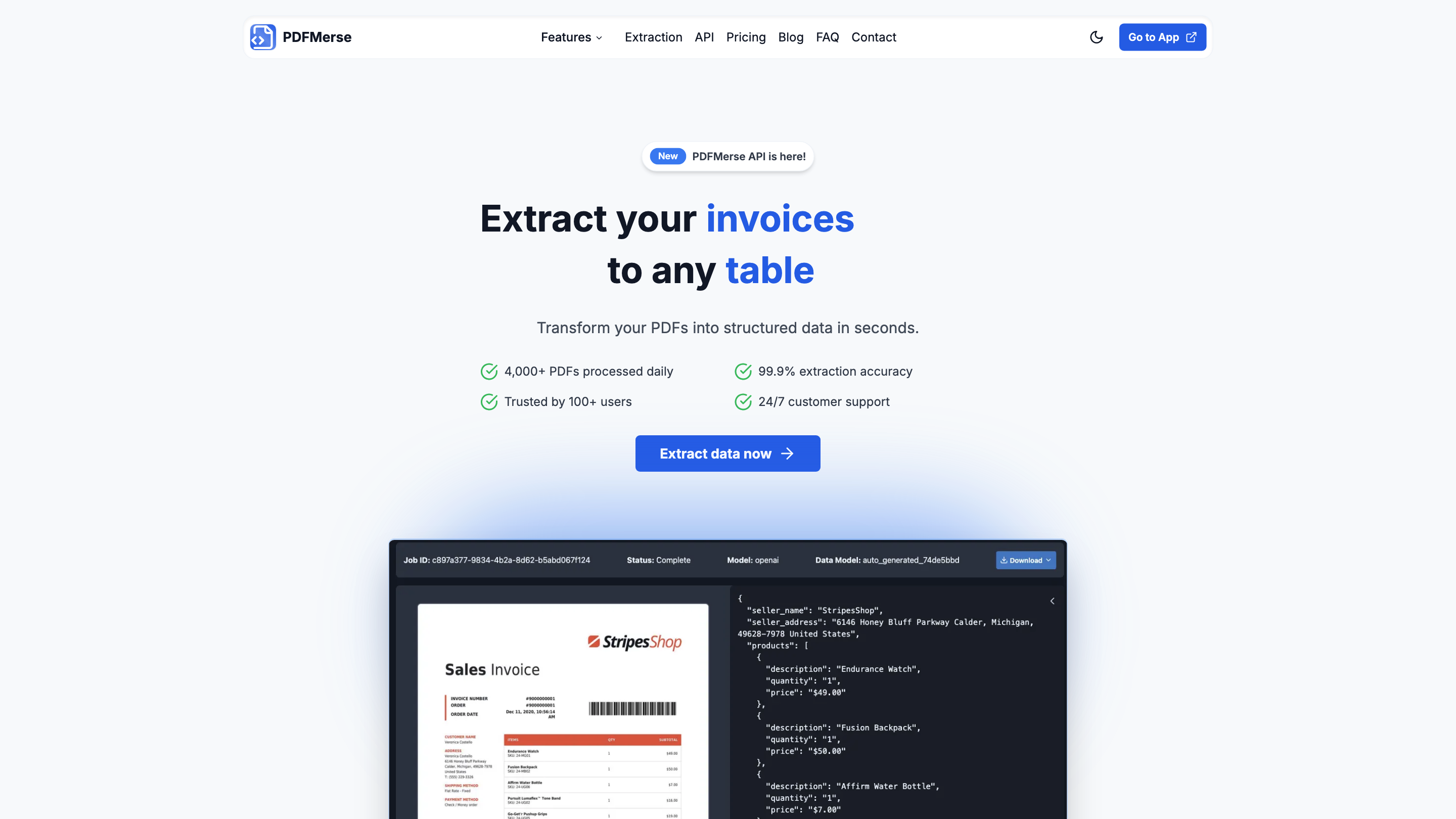
PDFMerse is an AI-powered PDF data extractor that transforms any PDF into structured data in seconds. It processes thousands of PDFs daily with high accuracy and offers multiple output formats, RESTful API access, and multilingual support to fit diverse workflows.
Key Capabilities
- Automated data extraction from a variety of PDFs (invoices, medical records, legal documents, etc.)
- Guaranteed structured data ready for immediate use in your systems
- Multi-language support and handwriting recognition for broader document types
- Output formats include JSON, CSV, and Excel, with plans for additional formats
- High-performance API designed for large-scale PDF processing
- Security-focused: reliable extraction designed for enterprise use
How It Works
- Upload or send PDFs to PDFMerse. The AI automatically identifies data fields based on the model and your input.
- Data is extracted and structured into a defined format, ready for integration.
- Retrieve the output in your preferred format via the API or download manually.
Use Cases
- Automate data entry from invoices, receipts, and purchase orders
- Extract patient or clinical data from medical records
- Capture legal document details and create searchable records
- Integrate extracted data into databases, CRMs, or analytics tools
Features
- Automated Data Extraction: AI-driven extraction reduces manual entry time.
- Guaranteed Structured Data: Always delivered in a defined, usable structure.
- Extraction Validation: Built-in checks ensure accuracy and consistency.
- Automated Data Model: Describe what to extract and the AI builds the model automatically.
- Multilanguage Support: Process documents in multiple languages.
- Handwritten Text Support: Recognizes printed and handwritten text.
- RESTful API: Easy integration with simple HTTP requests.
- Structured, Guaranteed Output: JSON output with a guaranteed format for safe app integration.
- High Performance: Optimized for speed and large volumes.
- Secure & Reliable: Focus on data accuracy and secure processing.
How to Use the PDFMerse API
- Choose a plan: Free, Basic, Professional, or Enterprise based on page volume and feature needs.
- Use the RESTful API to send PDFs and receive structured data in JSON (or other supported formats).
- Leverage custom data models to tailor extraction to your workflows.
Plans & Pricing (Summary)
- Free: Limited access, up to a small number of pages, JSON output, community support.
- Basic: $5/month, up to 100 pages/month, JSON output, API access, community support.
- Professional: $29/month, up to 1,000 pages/month, multiple output formats, advanced data model creation, full API access (2,000 credits/month).
- Enterprise: $79/month, unlimited pages, all output formats + full API access, 24/7 support, dedicated account manager, custom integrations.
Safety and Data Security
- Data handling is designed for enterprise use with secure and reliable processing.
FAQ Highlights
- What PDFs can be processed? Various types including scanned and native PDFs.
- How accurate is extraction? High accuracy with validation built-in.
- What output formats are supported? JSON, and plans for CSV/Excel (existing or upcoming).
- Is data secure? Yes, designed for secure and reliable extraction.
Getting Started
Extract data from PDFs quickly with PDFMerse’s AI-powered extraction API and transform your documents into actionable data.