PostgresML
Open siteIntroduction
Fast, simple, and powerful MLops platform.
PostgresML Product Information
PostgresML: In-database Machine Learning for PostgreSQL" is an open-source platform that brings end-to-end ML and AI capabilities directly into a PostgreSQL-based workflow. It integrates vector databases, embeddings, LLMs, RAG search, and supervised learning tasks, enabling you to index, filter, and rank vectors, generate embeddings, train and tune models, and deploy them inside the data store. The solution emphasizes performance, data privacy, and operational simplicity by colocating data processing, embeddings, and model serving in a single environment. It provides multiple deployment options (including cloud, VPC, and on-prem) and supports a wide range of models and libraries, all accessible via SQL or SDKs in Python/JS.
How it Works
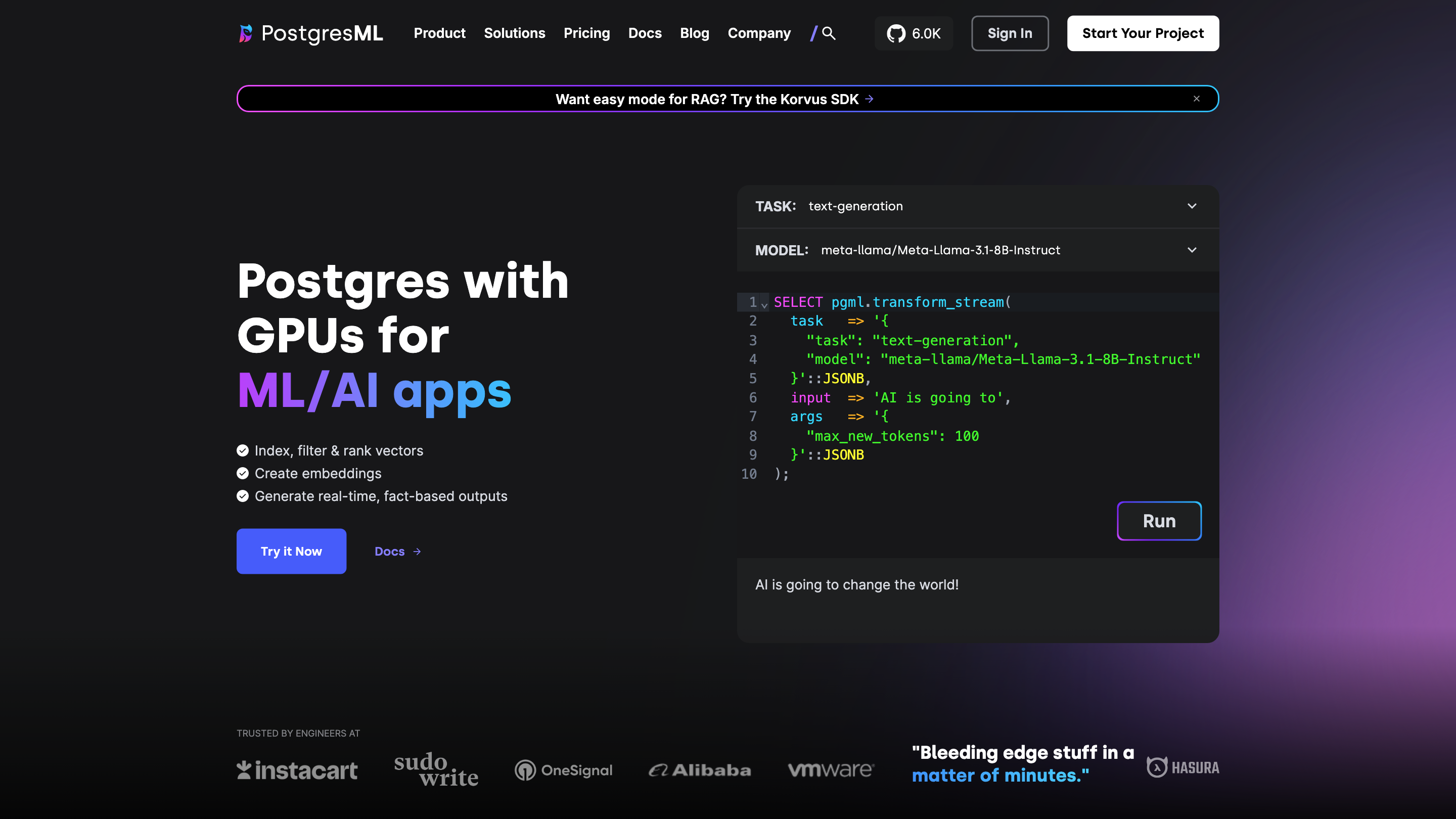
- Index, filter & rank vectors. Build and query vector embeddings with fast KNN/ANN search using HNSW or IVFFlat indexes.
- Generate embeddings. Use state-of-the-art models to convert text and other data into vector representations.
- Colocate data & compute. Run embedding, serving, and storage in one process for terabytes of data on a single machine.
- Train & deploy models. Train, fine-tune, and deploy regression, classification, clustering, and LLMs on your data.
- Privacy & security. Built-in data privacy controls; your data can stay within your trusted environment.
Core Use Cases
- Vector search and RAG for intelligent retrieval
- In-database embeddings generation and management
- In-database model training, evaluation, and deployment
- Chatbot and QA solutions with real-time, fact-based outputs
- End-to-end ML workflows without leaving PostgreSQL
Getting Started
- Choose deployment option (Cloud, VPC, or On-Prem) and connect to your PostgreSQL-compatible database.
- Install the PostgresML extension and optional Korvus SDK for easier RAG workflows.
- Select models for embeddings and LLMs, configure data preprocessors, and start building pipelines inside SQL/Python/JS.
Safety and Compliance
- In-database processing helps minimize data movement and exposure. Always configure access controls and audit trails in your deployment environment.
Core Features
- In-database ML/AI: train, fine-tune, and deploy models directly inside PostgreSQL
- Vector database integration: index, filter, and re-rank embeddings with fast KNN/ANN (HNSW/IVFFlat)
- Embeddings generation: convert text/data to vector representations using state-of-the-art models
- End-to-end RAG workflows: support for retrieval-augmented generation
- In-database privacy: data remains within the database environment
- Multiple deployment options: Cloud, VPC, and on-prem setups
- SQL/SDK interoperability: use SQL, Python, and JavaScript to build ML pipelines
- Broad model and library support: LLMs, embeddings, and ML frameworks
- In-database training & evaluation: regression, classification, clustering, and more
- Real-time deployment: serve models with low latency inside PostgreSQL