Thunder Compute
Open siteCoding & Development
Introduction
Serverless GPU cloud for running code efficiently and instantly.
Featured
ElevenLabs
The voice of technology. Bringing the world's knowledge, stories and agents to life
Chatbase
Chatbase is an AI chatbot builder that uses your data to create a chatbot for your website.
Lovable
AI-powered platform for software development via chat interface.
Wan AI
Video & Image Generation Model from Alibaba Cloud
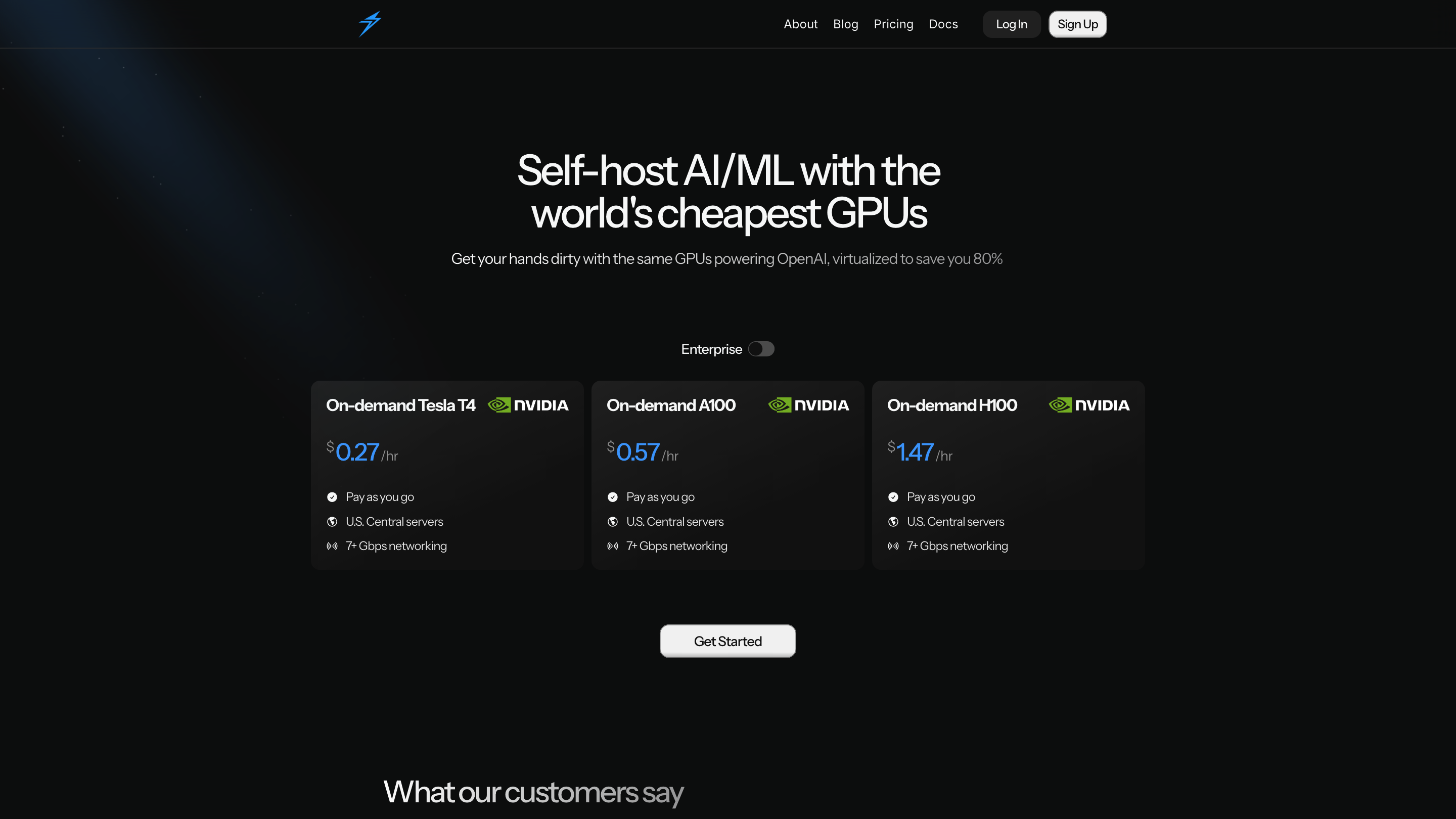
Thunder Compute Product Information
Thunder Compute is a self-hosted AI/ML GPU cloud that lets you run AI models on the same GPUs powering OpenAI, virtualized to save you up to 80% compared to traditional cloud providers. It targets teams and individuals who want cost-efficient, on-demand GPU power with an emphasis on ease of use, speed, and local control.
Overview
- Access enterprise on-demand GPUs (Tesla T4, A100, H100) in the U.S. Central region with 7+ Gbps networking.
- Pay-as-you-go pricing: Tesla T4 at 0.27/hr, A100 at 0.57/hr, H100 at 1.47/hr.
- Self-host AI/ML workloads without long-term commitments or vendor lock-in.
- Features designed to simplify deployment, management, and scaling of GPU-backed AI projects.
How It Works
- One command creates a GPU instance with the required specs using a fast CLI.
- Quick-start templates and integrations help you get up and running with common AI/ML stacks.
- Manage, connect, and scale instances as your workloads grow, with dedicated tooling for easy operations.
- Real customer testimonials highlight cost savings and ease of setup compared with other cloud providers.
Getting Started
- Use the CLI to create a GPU instance with your desired specs.
- Connect to the instance and install the models and tools you need (eg. Ollama, Comfy-ui, VS Code integration).
- Manage, deploy, and scale your AI workloads directly from Thunder Compute.
What You Get
- Cheap, on-demand GPU instances for AI/ML development and inference
- CLI-driven provisioning and management for speed and repeatability
- Pre-configured instance templates to quickly set up common tools
- Easy local development workflows with VS Code integration and remote access
- Competitive pricing and a focus on cost-efficiency without sacrificing performance
Safety and Compliance
- Use within applicable laws and terms; manage data responsibly when running models and storing results.
Core Features
- On-demand GPU instances (Tesla T4, A100, H100) in the U.S. Central region with high-speed networking
- Pay-as-you-go pricing to minimize up-front costs
- One-command GPU instance creation for rapid bootstrapping
- CLI-based management for Create, Connect, Manage lifecycle
- Preconfigured instance templates for tools like Ollama, Comfy-ui, and code editors
- VS Code integration for seamless local-remote development
- Resources and docs to simplify AI/ML development and deployment