Trieve
Open siteCoding & Development
Introduction
AI infrastructure for search and recommendations integration.
Trieve Product Information
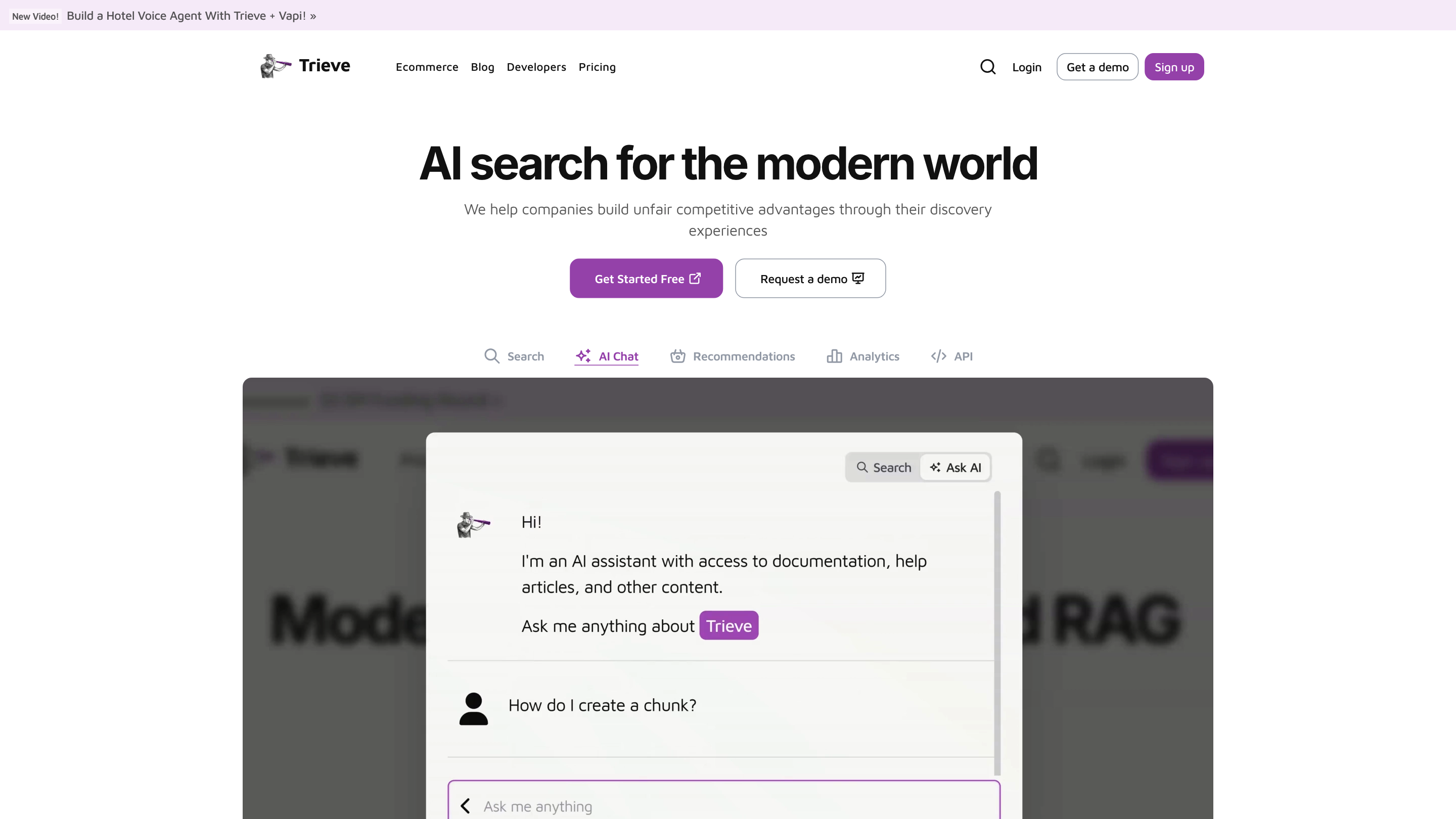
"Trieve" is an AI-first infrastructure API for search, recommendations, and RAG that combines language models with tooling to fine-tune ranking and relevance. It powers discovery experiences at scale and offers modular, self-hostable capabilities for developers and enterprises. Key offerings include semantic vector search, traditional full-text search, and hybrid retrieval, all designed to deliver fast, relevant results while keeping data private.
What it does
- Provides end-to-end discovery capabilities: chunking, ingestion, search, recommendations, RAG, and lightweight front-end support.
- Supports multiple retrieval models:
- Semantic vector search out of the box
- BM25 & SPLADE full-text search
- Flexible embedding strategy:
- Stock and custom embedding models
- Bring-your-own embedding models
- Hybrid search combines full-text with semantic signals and cross-encoder re-ranking for improved relevance.
- Merchandising and relevance tuning to optimize search results against KPIs via API or no-code dashboard.
- Sub-sentence highlighting to quickly show users why results match their query.
- Private, open-source models with on-premises hosting to prevent data leakage.
- Batteries included: a complete API surface for ingestion, search, recommendations, RAG, plus frontend support.
How it works
- Add existing data by chunking documents and uploading through the API or no-code dashboard.
- Integrate the API into your create/update routes to keep data current.
- Use search, recommendations, or generate capabilities, and test/tune with the search playground before deployment.
Why choose Trieve
- Self-hostable with Terraform templates and no external dependencies for maximum control and performance.
- Private data handling: open-source models run on your infrastructure, ensuring data never leaks.
- Fast onboarding: designed to get industry-leading search up and running in about 30 minutes.
- No vendor lock-in: flexible, modular API surface suited for diverse discovery use cases.
Feature highlights
- Semantic vector search out of the box
- BM25 & SPLADE full-text search
- Stock and custom embedding models; bring-your-own embeddings
- Hybrid search with cross-encoder re-ranker support
- Merchandising & relevance tuning via API or no-code dashboard
- Sub-sentence highlighting for precise result comprehension
- Private open-source models with self-hosted deployment
- Comprehensive API surface: chunking, ingestion, search, recommendations, RAG, and frontend
- Self-hostable with Terraform templates and no external dependencies